Software > OpenVMS Systems > Documentation > 82final > 6297 HP OpenVMS Systems Documentation |
HP COBOL
|
| Previous | Contents | Index |
Each random access request begins by comparing a key value to the root bucket's entries. It seeks the first root bucket entry whose key value equals or exceeds the value of the access request key. (This search is always successful, because the root bucket's highest key value is the highest possible value that the key field can contain.) Once that key value is located, the bucket pointer is used to bring the target bucket on the next lower level into memory. This process is repeated for each level of the index.
One bucket is searched at each level of the index until a target bucket is reached at the data level. The data record's location is then determined so that a record can be retrieved or a new record written.
A data level bucket may not be large enough to contain a new record. In this case, the I/O system inserts a new bucket in the chain, moving enough records from the old bucket to preserve the key value sequence. This is known as a bucket split.
Data bucket splits can cause index bucket splits.
I/O optimization of an indexed file depends on five concepts:
Variable-length records can save file space: you need write only the primary record key data item (plus alternate keys, if any) for each record. In contrast, fixed-length records require that all records be equal in length.
For example, assume that you are designing an employee master file. A variable-length record file lets you write a long record for a senior employee with a large amount of historical data, and a short record for a new employee with less historical data.
In the following example of a variable-length record description, integer 10 of the RECORD VARYING clause represents the length of the primary record key, while integer 80 describes the length of the longest record in A-FILE:
FILE-CONTROL.
SELECT A-FILE ASSIGN TO "AMAST"
ORGANIZATION IS INDEXED.
DATA DIVISION.
FILE SECTION.
FD A-FILE
ACCESS MODE IS DYNAMIC
RECORD KEY IS A-KEY
RECORD VARYING FROM 10 TO 80 CHARACTERS.
01 A-REC.
03 A-KEY PIC X(10).
03 A-REST-OF-REC PIC X(70).
.
.
.
|
Buckets must contain enough room for record insertion, or bucket splitting occurs. The I/O system handles it by creating a new data bucket for the split, moving some records from the original to the new bucket, and putting the pointer to the new bucket into the lowest-level index bucket. If the lowest-level index bucket overflows, the I/O system splits it in similar fashion, on up to the top level (root level).
In an indexed file, the I/O system also maintains chains of forward pointers through the buckets.
For each record moved, a 7-byte pointer to the new record location remains in the original bucket. Thus, bucket splits can accumulate overhead and possibly reduce usable space so much that the original bucket can no longer receive records.
Record deletions can also accumulate storage overhead. However, most of the space is available for reuse.
There are several ways to minimize overhead accumulation. First, determine or estimate the frequency of certain operations. For example, if you expect to add or delete 100 records of a 100,000-record file, your database is stable enough to allow some wasted space for record additions and deletions. However, if you expect frequent additions and deletions, try to:
Each alternate key requires the creation and maintenance of a separate index structure. The more keys you define, the longer each WRITE, REWRITE, and DELETE operation takes. (The throughput of READ operations is not affected by multiple keys.)
If your application requires alternate keys, you can minimize I/O processing time if you avoid duplicate alternate keys. Duplicate keys can create long record pointer arrays, which fill bucket space and increase access time.
Bucket size selection can influence indexed file performance.
To the system, bucket size is an integral number of physical blocks, each 512 bytes long. Thus, a bucket size of 1 specifies a 512-byte bucket, while a bucket size of 2 specifies a 1024-byte bucket, and so on.
The HP COBOL compiler passes bucket size values to the I/O system based on what you specify in the BLOCK CONTAINS clause. In this case, you express bucket size in terms of records or characters.
If you specify block size in records, the bucket can contain more records than you specify, but never fewer. For example, assume that your file contains fixed-length, 100-byte records, and you want each bucket to contain five records, as follows:
BLOCK CONTAINS 5 RECORDS |
This appears to define a bucket as a 512-byte block, containing five records of 100 bytes each. However, the compiler adds I/O system record and bucket overhead to each bucket, as follows:
| Bucket overhead | = 15 bytes per bucket |
| Record overhead |
= 7 bytes per record (fixed-length)
9 bytes per record (variable-length) |
Thus, in this example, the bucket size calculation is:
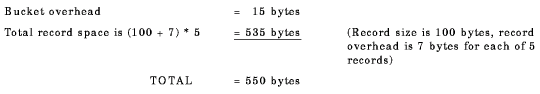
Because blocks are 512 bytes long, and buckets are always an integral number of blocks, the smallest bucket size possible (the system default) in this case is two blocks. The system, however, puts in as many records as fit into each bucket. Thus, the bucket actually contains nine records, not five.
The CHARACTERS option of the BLOCK CONTAINS clause lets you specify bucket size more directly. For example:
BLOCK CONTAINS 2048 CHARACTERS |
This specifies a bucket size of four 512-byte blocks. The number of characters in a bucket is always a multiple of 512. If not, the I/O system rounds it to the next higher multiple of 512.
The length of data records, key fields, and buckets in the file determines the depth of the index. Index depth, in turn, determines the number of disk accesses needed to retrieve a record. The smaller the index depth, the better the performance. In general, an index depth of 3 or 4 gives satisfactory performance. If your calculated index depth is greater than 4, you should consider redesigning the file.
You can optimize your file's index depth after you have determined file, record, and key size. Calculating index depth is an iterative process, with bucket size as the variable. Keep in mind that the highest level (root level) can contain only one bucket.
If much data is added over time to an indexed file, you should reorganize the file periodically to restore its indexes to their optimal levels.
Following is detailed information on calculating file size, and an example of index depth calculation:
Use these calculations to determine data and index record size:
If a file has more than 65,536 blocks, the 3-byte index record overhead could increase to 5 bytes.
Use these calculations to determine SIDR record length:
Bucket packing efficiency determines how well bucket space is used. A packing efficiency of 1 means the buckets of an index are full. A packing efficiency of .5 means that, on the average, the buckets are half full. |
Consider an indexed file with these attributes:
Primary key index level calculations:
In the following calculations, some results are to be rounded up, and some truncated.

| Previous | Next | Contents | Index |