Software > OpenVMS Systems > Documentation > 82final > hanzi > vmshanzi_user_htm HP OpenVMS Systems Documentation |
OpenVMS/Hanzi
|

���ܼ���������������� HP �������Ч����֤������ӵ�С�ʹ�û��Ʊ����������ݹ�Ӧ�̵ı���ҵ����֤�Ĺ涨����������Ӧ���� FAR 12.211 �� 12.212���йء���ҵ�������������������������ĵ����롰��ҵ���\�����ݡ�����Ĺ涨��
���ĵ��е���Ϣ���и��ģ�ˡ������֪ͨ���� HP ��Ʒ�������ṩ����ʾ�Ե����������г��������ڴ� HP ��Ʒ�������ר�õ�����������е��κ����ݾ������ɶ���ĵ�����HP �Ա����еļ�����༭�����Լ�ȱ©�����κ����Ρ�
Intel �� Itanium �� Intel Corporation �����ӹ�˾���������������һ�������̱��ע���̱ꡣ
3.3.3 ֧�� ODL ����Ҫ��ϵͳ���� 3-3
3.3.4.2 �� HANZIGEN �����ն˶˿� 3-5
4.2.3 APPEND��BACKUP��CONVERT��COPY��CREATE ��TYPE ��
ʹ�ú��� 4-2
4.2.4 ASSIGN��DEASSIGN �� DEFINE ��ʹ�ú��� 4-2
4.2.7 OpenVMS HELP ��ʹ�ú��� 4-3
4.2.8 READ �� WRITE ��ʹ�ú��� 4-3
4.3 ͨ�� PostScript ��ӡ��ϵͳ 4-5
�� 6 �� �ַ��������� (CMGR) ���ó���
7.3.2 /SPECIFICATION ���� 7-3
7.7 �ɵ���SORT �� MERGE ���г����еĺ���֧�� 7-6
8.3.5 �����������е��ļ�������ʾ 8-3
8.3.6 ���� HTPU ��ΪĬ�ϱ༭���� 8-6
11.8.3 RTL ����/ʱ��������г��� 11-6
A.1 �� MACRO-32 ��ʹ�ú��ֵ����� A-1
A.2 �� DEC FORTRAN ��ʹ�ú��ֵ����� A-3
A.3 �� BASIC ��ʹ�ú��ֵ����� A-4
A.4 �� PASCAL ��ʹ�ú��ֵ����� A-5
B.1.1 ʹ�ÿɵ��� HSYSHR ���г�������� B-1
B.3 SORT �� MERGE �ɵ������г��� B-7
B.3.3 ʹ�ÿɵ��� SORT �� MERGE ���г�������� B-10
B.3.3.1 ʹ��ƴ���������е��� SORT ���г���ij��� B-10
B.3.3.2 ʹ�ö����������е��� SORT ���г���ij��� B-11
B.3.3.3 ���� MERGE �����ij��� B-13
OpenVMS/Hanzi �����е� OpenVMS �������������Ӻ����ַ���������������,�û����ڸ��� OpenVMS/Hanzi �����´��� ASCII �� DEC �����롣
OpenVMS/Hanzi ֧����˫�ֽڰ���λ��ʽ��ʾ����������,�����л��������ұ���Ϣ�����ú��ֱ����ַ�������(GB-2312-80)���й� DEC �����ַ���������,����ı��ֲ�� 2 �¡�
�� OpenVMS/Hanzi ��, �ֵ� OpenVMS DCL���֧�ֺ����ַ����й���Щ�������ϸ����,����ĵ� 3, 4, 6, 7, 8, 9��10��11 �� 12 �¡��û�Ҳ���ڶ��ֱ������д�ɵij���ʹ�ú��֡���¼ A ���ж����������ο���
OpenVMS/Hanzi �ṩ�������ܹ����������ַ��Ĺ��ó���, ����:
HANZIGEN ���ó�������ò���ʾ�����ն����͡���Ҳ���ṩ���ƣ����û�Ϊ���ó���ѡ�����ԡ�
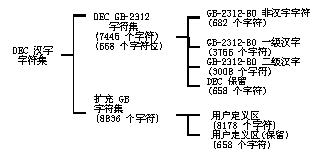
DEC �����ַ����ǰ������ֺͷǺ����ַ��Ļ����ַ���, �� GB-2312-801 ���ݡ�
DEC �����ַ�����Ϊ������ -- DEC GB-2312�ַ��������� GB �ַ���, ���� 7,445 ���ַ��� 8,836���ַ�λ��
���� GB �ַ�����һ����������, �� 8,836 ���ַ�λ���û������Լ�������,���Ժ������ַ���֮�á�
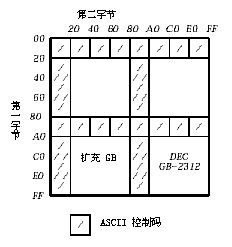
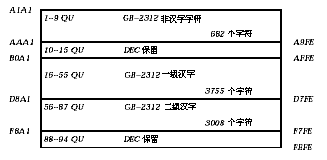
�� 2-1 �� 2-2 �г� DEC �����ַ����ڸ�����Ķ��塣
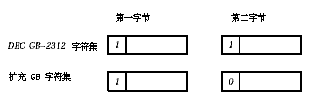
DEC ��������˫�ֽڱ�ʾһ��ͼ���ַ���Ϊ���������һ��� ASCII ��, һ���ַ��ĵ�һ�ֽڵ������Чλ��������Ϊ 1,���ڶ��ֽڵ������Чλ������� 1 (���ַ����� DEC GB-2312 �ַ������� 0�����ַ��������� GB �ַ�������
ͼ 2-2 չʾһ�������� DEC GB-2312 �ַ��������� GB �ַ����еı�ʾ������
DEC ��������� GB-2312-80 ����DEC GB-2312 �ַ��������� GB �ַ����Ĵ����������Ϊ 94 ����(��), ����� 1 �� 94��ÿ�����ַ�Ϊ 94 ��λ,���Ҳ�� 1 �� 94��
DEC ������ĵ�һ�ֽھ������������,���ڶ��ֽ�����������λ�š�����,�ڶ��ֽڵ������Чλ�������������� DEC GB-2312�ַ����������� GB �ַ�����
������������˵���� DEC GB-2312 �ַ��������� GB �ַ�����һ�������ַ���˫�ֽں��������λ�ŵ����ϵ��ͨ��,���ż�λ����ʮ���Ƶ�,��˫�ֽں���������ʮ�����Ʊ�ʾ��
���� (ʮ����) = ��һ�ֽ� (ʮ������) - A0 (ʮ������) ��
λ�� (ʮ����) = �ڶ��ֽ� (ʮ������) - A0 (ʮ������)
���� 16��λ�� 1 �͵��� DEC ������ B0A1��
���� (ʮ����) = ��һ�ֽ� (ʮ������) �� A0 (ʮ������) ��
OpenVMS/Hanzi ֧�����к����ַ����ն�������������:
OpenVMS/Hanzi ��֧�������� OpenVMS ֧�ֵ��б༭����,�������ƶ���ɾ�������롢�ؼ��Լ����ƻء��й�������֧������,����� OpenVMS ���ס�
�ն���Ļ����ʾ�ĺ����ַ�ռ�ݵ�λ�ö���һ�С����, OpenVMS/Hanzi �ṩ���ֲ���̬���б༭:
�ڴ�̬��,�ں����ն���ɾ����һ��ɾ��һ�С�����ƶ���һ���ƹ�һ�С�
�ڴ�̬��,ɾ����һ��ɾ��һ���ַ�������ƶ���һ���ƹ�һ�������ַ�����ɾ���ּ� (CTRL/J) ��ɾ��һ��Ӣ���ֻ�һ�������ַ���
���������û����ȫ�����������ַ�̫������ʾ(����, ��ĩβֻ��һ����ʾ��Ԫ ����,����������һ�������ַ�)���������ĺ��ֻᱻ�ݴ�����Ϊ��һ�ζ���Ҫ����������롣
HANZIGEN ���ó��������������ֱ༭̬֮�����ת�����й�ת��̬������, ����ĵ� 5 �¡�HANZIGEN ���ó���
�����Ը���Ӧ�ó���ָ���Ĺ���У���������ݡ�
Ӧ�ó����ָ��һ���ñ�Ƿֳ�һ�����ϵ��������������ֶΡ���� DEC GB-2312 �ַ����еĺ����ַ����ڱ�Ƕ���Ľ��� (Ҳ����˵, ������ֳ������� ���벻ͬ������),���ͱ���Ϊ��Ч�ַ���
OpenVMS/Hanzi ��Ϊ�û��ṩ CMGR ���ó��� (����ĵ� 6 �¡��ַ��������� (CMGR) ���ó���)�����û������ַ� (UDC)����Щ�ַ��������������� OpenVMS/Hanzi ֧�ֵĺ��ֱ������ַ���
Ϊ��Ҫ���ն˻��ӡ������ʾ��Щ�ַ�, OpenVMS/Hanzi֧�������ն���������İ���װ�� (ODL) Э�顣֧�� ODL Э����ն˺ʹ�ӡ�����Զ�ж�� UDC ������������ʾ UDC��
LAT/Master ���� LAT ������֧�� ODL ����Ҫ������,������ OpenVMS/Hanzi �����е��������ն˷����������е�������
Ϊ��ʹ ODL �� LAT �����ϲ���, ��������°汾��DECserver ��������װ���Ӧ�ķ�������Ԫ:
Ҫ���� LAT ����, ��ȷ������װ��������װ����ȷ��DECserver �����汾�Լ���ϵͳ���� OpenVMS��
Ҫ�˽������װ�������ϰ�װ DECserver �����Ͱѷ�����ӳ������װ�������, ������� DECserver �ṩ���й����ס�
ODL ����Ҫ��ϵͳ����α�豸 FHA0: �� FONT_HANDLER��
SYSGEN> CONNECT FHA0: /NOADAPTER /MAXUNIT=1
/PROCESS_NAME="FONT_HANDLER" -
OpenVMS/Hanzi �ϵ� SYSGEN ����Ϊ������������װ���װ��һ��α�豸������������һ��α�豸 FHA0:��RUN �����һ��ϵͳ���� FONT_HANDLER Ϊ�ն˼���ӡ���İ���װ���������
ע��, ��Щ�����ѱ༭�� OpenVMS/Hanzi ϵͳ��������� SYS$STARTUP:HSY$STARTUP.COM ��, ������������, OpenVMS/Hanzi ϵͳ�� ODL ��������ȷ�ġ�
����豸���ն˷�����������,�����ǡ���������ն˷������˿ڡ�
����ֱ�����ӻ���һ���ն˷����������ӵ��豸,ϵͳ�е�ÿ���ն˶˿ڱ���� ODL���и������á�ͨ��,�ն˶˿ڶ� ODL ��Ĭ��ֵΪ���� ODL��HANZIGEN ���ó��������Ը����ն� (������ HANZIGEN �����ն˶˿�һ��) ���� ODL���ն˻��ӡ��ҲҪ�����ã��Ա������ն˻��ӡ���� ODL ������
DECserver ������, Ϊ ODL ֧�������¶˿����� ON-DEMAND [LOADING]�����ʹ���û�����ÿ���뺺���ն˻��ִ�ӡ�������ӵķ��������������� ODL ������Ҫ��һ������˿��������� ODL, ���� Local ̬������������:
Local> {SET|DEFINE} PORT [n] ON-DEMAND [LOADING]
����, Ҫ�Զ˿� 3 ���õ����� ODL ����(������Щ���ô洢���������ݿ���), ��:
Local> DEFINE PORT 3 ON-DEMAND LOADING ENABLED
|
Ҫ�� DECserver 500���������õ�����,����Ҫ��װ��������ִ���ն˷��������ó��� (TSC)�� |
ҪУ���Ƿ������� ON-DEMAND [LOADING] ����, ���� Local ̬���� LIST PORT CHARACTERISTICS ����:
Local> LIST PORT CHARACTERISTICS
Character Size: 8 Input Speed: 9600
Flow Control: XON Output Speed: 9600
Parity: None Modem Control: Disabled
Access: Local Local Switch: None
Forwards Switch: None Type: Soft
Autobaud, Autoprompt, Broadcast, Input Flow
Control, Loss Notification,Massage Codes, Output
�� OpenVMS/Hanzi ��, ʹ�� HANZIGEN ���ն˶˿������� ODL���й�ʹ�� HANZIGEN �����������ͳ��� ODL ������, ����ĵ� 5 �¡�HANZIGEN ���ó���һ�¡����� "/FONT" �� "/NOFONT" �� HANZIGEN ������������������װ�롣����Ĭ���dz�������װ�롣��������Ե�ǰ�ն�
�ں����ն������� ODL, ��Ҫ�������в���:
�� <F3> ���Խ��� "����Ŀ¼",Ȼ��ѡ�� "�ն�" ���ò����� "�ն�����" ��Ŀ�������� ODL��
����һ���Ի������г��ĺ��ִ�ӡ�������� ODL, ��Ҫ�������в���:
HANZIGEN> SET/DEVICE_TYPE=LA380/FONT/PERMANENT LTA100:
�����г������ն˼����ִ�ӡ��������豸����,�������� DCL ������ó��������Ӧ�ú����ַ���
����˵���� DCL ���������ʹ�ú����ַ���
������ʹ������ SHOW ����, �Ժ�����ʾϵͳ����:
�� OpenVMS ������Ϣ����, �û�����Ӧ�� HANZIGEN ���ó�����ѡ��Ӣ�Ļ�����Ϣ, Ψ SHOW LOGICAL �� SHOW TRANSLATION ���⡣
�û������ļ���ʹ�ú�������, ������APPEND��BACKUP��CONVERT��COPY��CREATE �� TYPE�����а������֡�����:
���������������Ч�ַ�����ʹ�ú���, Ҳ���� ASSIGN��DEASSIGN��DEFINE ������ʹ�ú��֡�
������ SHOW LOGICAL �� SHOW TRANSLATION ������ʾ�� ASSIGN �� DEFINE �Ժ����ַ����������, ���ʷ����� F$LOGICAL ���ת�����֡�����:
����ʹ�� HELP ����� HANZIGEN ���ó��������� OpenVMS HELP ��ʩ, �Ժ��ֻ�Ӣ����ʾ�й� OpenVMS �������Ŀ�����ϡ�
ע��, ����ʹ����������ֱ����ʾӢ������ (��ʹ��������豸���ó� HANZI_MSG):
���������ַ������ݿ��Թ������������ı���һ���֡�����:
$ OPEN/WRITE OUTPUT HANZI1.DAT
$ REPLY/TERMINAL=TT "REPLY �л�Ϻ���ʹ��"
ͨ�� PostScript ��ӡ��ϵͳ (WWPPS) �ṩ�� Alpha �� I64 ƽ̨�ϴ��ı��ļ��ĸ�������ӡ�����ܹ�ͬʱ��ӡ�������ֽںͶ��ֽ������ַ��Ĵ��ı��ļ���
Ҫ����������ó����������� DCL ��ʾ��ʹ���������
���⣬������ͨ�����������ⲿ�����������ã�
$ WWPPS := = $SYS$SYSTEM:WWPPS
WWPPS>PRINT/QUEUE=hp$printer/LOCALE=zh_cn_dechanzi hanzi-text_file.txt
$ WWPPS PRINT/QUEUE=hp$printer/LOCALE=zh_cn_dechanzi hanzi-text_file.txt
�������� HANZIGEN ���ó���Ĺ��ܡ�
HANZIGEN ���ó������ü�չʾ�����ն����͡����������������ն˼���ӡ���İ���װ�롣
HANZIGEN �� SET �� SHOW ������ DCL ������, �� HANZIGEN ��SET �� SHOW ��������뺺���ն��йص����ԡ�
SET �������ú����ն����ͼ���������װ�롣�����ն����Ϳ�����VT82��VT382��LA84�� LA86��LA88��LA280 �� LA380��Ҫ���ú����ն�Ϊ ASCII ����, ����ָ�� VT100 �� VT300_seriesΪ�豸���͡������ṩӢ�ĺͺ�������/������Ϣ�Ĺ��ó���,����ʹ�� SET ����ͨ�� /OUTPUT��ѡ��ѡ��������ԡ�
SET [�豸��[ : ]] [/DEVICE_TYPE= �豸����]
SHOW ����չʾ�����ն˼���ӡ������,��ʾ��ʽ��ÿ���豸ռһ�У����Ҿ������ֶ�:
�� HANZIGEN �����, VT82 �� VT382
���豸���ͽ�չʾΪ HANZI_VDU, �� LA84-C��LA86-C��LA88-C��LA280-CB �� LA380-CB���豸������Ϊ HANZI_PRT��
����, �� DCL SHOW ������, ���� HANZIGEN ����ΪVT82 ��VT382 �ն˵��豸���� VT80 �� VT300, ���� HANZIGEN ����Ϊ LA84��LA86��LA88��LA280 �� LA380 �ն˵��豸������ LA84��
Device Name Type On Demand Input Output
_RTA2: HANZI_VDU DISABLE ASCII HANZI_MSG
Device Name Type On Demand Input Output
_OPA0: LA36 DISABLE ASCII Unknown
_RTA1: VT300_Series DISABLE HANZI Unknown
_RTA2: HANZI_VDU DISABLE ASCII HANZI_MSG
_LTA5006: VT200_Series DISABLE HANZI Unknown
_LTA5007: HANZI_VDU DISABLE ASCII Unknown
_LTA5008: HANZI_VDU DISABLE ASCII Unknown
Device name Type On Demand Input Output
_TTA0: VT200_series DISABLE ASCII ASCII_MSG
HANZIGEN> SET /DEVICE_TYPE=VT382
Device name Type On Demand Input Output
_TTA0: HANZI_VDU DISABLE HANZI HANZI_MSG
HANZIGEN> SET TXA1: /DEVICE_TYPE=LA380 /PERMANENT /FONT
Device name Type On Demand Input Output
_TXA1: HANZI_PTR ENABLE HANZI Unknown
Device name Type On Demand Input Output
_TAX2: HANZI_VDU DISABLE HANZI Unknown
HANZIGEN> SET TXA2: /DEVICE_TYPE=VT100 /PERMANENT
���������ַ��������� (CMGR) ���ó�������ԡ�
�������� OpenVMS/Hanzi SORT �� MERGE ���ó������ṩ�ĺ��ִ���������
OpenVMS/Hanzi �� SORT �� MERGE���ó�������û���ָ���Ĺؼ��������������ļ���¼,Ȼ�����һ�������������ļ���SORT �� MERGE�ɰ��������������������к������ݼ�¼:
|
��ָ���ĺ����ֶ��Բ�����������ͺϲ��������ַ����� GB-2312-80 ���IJ���������������� |
|
|
��ָ���ĺ����ֶ���ƴ����������ͺϲ��������ַ����� GB-2312-80 ����ƴ���������༰���� |
|
ע��: �����������������ݼȲ�����Ч�� DEC �����ַ�, �ֲ��� UDC,��ϵͳ��������ݷ���һ��Ϊ�������ֵ��
input-file-specification[qualifiers] -
_$ output-file-specification[qualifiers]
input-file-specifications[qualifiers] -
_$ output-file-specification[qualifiers]
�ںϲ�ǰ, MERGE������������ļ���������ͬһ���������м�ͬһ�ִ���(�������) Ԥ������MERGE������ָ������������������б����������ļ�����ͬ��
/KEY ���ʶ��� SORT �Ĺؼ���,��һ�����������ɳ��� 255 �Ρ���Բ���Ű� /KEY ��������������
������ OpenVMS SORT �� MERGE ���ṩ��֮��, OpenVMS/Hanzi �� SORT �� MERGE ��֧�����������ʡ�
|
SORT �� MERGE �� CSIZE������ֻ�����ں����������С�n �� SORT �� MERGE �ؼ��ֵ��ַ������ȡ�ע��, ������һ���ؼ���˵����ͬʱָ�� CSIZE �� SIZE�� |
|
/KEY=(POSITION:1, CSIZE:5, RADICAL, STROKE)
������, RADICAL ������������; STROKE�Ǵ��������С� ע��, ͬʱ��ָ�����غ����������С�
OpenVMS/Hanzi �� SORT �� MERGE�ṩһ����������,ͨ�������ʴ���һ�������ļ�˵����˵���ļ���Ĭ���ļ�������.SRT��ָ�����ļ��������ʽ����:
$ SORT/SPECIFICATION=input-specification-file ...
�ڡ�OpenVMS User's Manual����,˵���ļ��ĸ�ʽ������������
˵���ļ��е� /FIELD ������������ SORT �� MERGE �ؼ����ֶΣ��� /KEY �������ʺ����ơ�����OpenVMS SORT �� MERGE ���ó����� /FIELD���ʵ�������Ч����������, OpenVMS/Hanzi SORT �� MERGE �������е�����Ч������:
��Щ��ʾ����Ӧ�������е������ʵ��� /KEY������������ͬ�����ʡ�������˵���ļ��� /FIELD���ʵ�һ������:
/FIELD=(NAME:Hanzi-field, POSITION:1, SIZE:4, PINYIN)
ע��, ��һ�� /FIELD �����ڲ���ָ������������С����Ҫ��һ���ؼ���ָ��������������,����˵���ļ��ж�ͬһ�ؼ���ָ����ͬ�������еĶ�� /FIELD ���ʡ�
������ !"��"��֮������ 72 ,�ʻ� 07 ,ƴ�� LI , ��λ 3278
���� !"��"��֮������ 119,�ʻ� 05 ,ƴ�� BAI , ��λ1655
��ά !"��"��֮������ 70 ,�ʻ� 04 ,ƴ�� WANG, ��λ 4585
��� !"��"��֮������ 72 ,�ʻ� 07 ,ƴ�� LI , ��λ 3278
�Ϻ�Ȼ !"��"��֮������ 65 ,�ʻ� 08 ,ƴ�� MENG, ��λ 3547
$ SORT/KEY=(POSITION:1,CSIZE:1,RADICAL)POET.DAT RADICAL.DAT
�Ϻ�Ȼ !"��"��֮������ 65 ,�ʻ� 08 ,ƴ��MENG, ��λ3547
��ά !"��"��֮������ 70 ,�ʻ� 04 ,ƴ��WANG, ��λ 4585
��� !"��"��֮������ 72 ,�ʻ� 07 ,ƴ��LI , ��λ 3278
������ !"��"��֮������ 72 ,�ʻ� 07 ,ƴ��LI , ��λ 3278
���� !"��"��֮������ 119,�ʻ� 05 ,ƴ��BAI , ��λ 1655
$ SORT/KEY=(POSITION:1,CSIZE:2,STROKE)POET.DAT STROKE.DAT
��ά !"��"��֮������ 70 , �ʻ� 04 ,ƴ�� WANG,��λ 4585
���� !"��"��֮������ 119, �ʻ� 05 ,ƴ�� BAI ,��λ 1655
��� !"��"��֮������ 72 , �ʻ� 07 ,ƴ�� LI ,��λ 3278
������ !"��"��֮������ 72 , �ʻ� 07 ,ƴ�� LI ,��λ 3278
�Ϻ�Ȼ !"��"��֮������ 65 , �ʻ� 08 ,ƴ�� MENG,��λ 3547
������ !"��"��֮������ 72 ,�ʻ� 07 ,ƴ�� LI , ��λ 3278
���� !"��"��֮������ 119,�ʻ� 05 ,ƴ�� BAI , ��λ 1655
��ά !"��"��֮������ 70 ,�ʻ� 04 ,ƴ�� WANG, ��λ 4585
��� !"��"��֮������ 72 ,�ʻ� 07 ,ƴ�� LI , ��λ 3278
�Ϻ�Ȼ !"��"��֮������ 65 ,�ʻ� 08 ,ƴ�� MENG, ��λ 3547
�Ÿ� !"��"��֮������ 72 ,�ʻ� 07 ,ƴ�� DU , ��λ 2237
$ SORT/KEY=(POSITION:1,CSIZE:2,STROKE,QUWEI) -_$ POET1.DAT STRQUWEI.DAT
��ά !"��"��֮������70 ,�ʻ� 04 ,ƴ��WANG, ��λ 4585
���� !"��"��֮������119,�ʻ� 05 ,ƴ��BAI , ��λ 1655
�Ÿ� !"��"��֮������72 ,�ʻ� 07 ,ƴ��DU , ��λ 2237
��� !"��"��֮������72 ,�ʻ� 07 ,ƴ��LI , ��λ 3278
������ !"��"��֮������72 ,�ʻ� 07 ,ƴ��LI , ��λ 3278
HMAIL �� OpenVMS MAIL ���ó��������ӵ�����,���������µĸ�������һ�������й� OpenVMS MAIL ���ó��������, ����ġ�OpenVMS User's Manual����
HMAIL ���û������ڸ������а��������ַ�������,�û� TENG Ҫ�Ժ��ָ����������ļ� FILE.TXT ���û� HANZI::LEE, ����������������:
HMAIL> send/personal_name="������, ��������̲�" file.txt
�� HMAIL ��, SEARCH ����ļ����ַ����� SELECT��SET FOLDER��DIRECTORY �Լ� READ ����� /SUBJECT_SUBSTRING ���ʾ���ʹ�ú��֡�����:

�� OpenVMS MAIL ��, �ļ�����ֻ���� ASCII ����������ʾ���� HMAIL ��, �û�����ָ�����ݺ�������������ʾ�ļ�������DIRECTORY/FOLDER ����������һ���µ�����
/COLLATING_SEQUENCE, �����:
���¹��������� /COLLATING_SEQUENCE ����µ�����:
�� DISK$USER:[USER]MAIL.MAI;1 �е��ļ����б�
HMAIL>directory/folder/collating=(stroke,radical)
�� DISK$USER:[USER]MAIL.MAI;1 �е��ļ����б�
HMAIL> directory/folder/collating=radical
�� DISK$USER:[USER]MAIL.MAI;1 �е��ļ����б�
HMAIL> directory/folder/collating=ascii
�� DISK$USER:[USER]MAIL.MAI;1 �е��ļ����б�
�����ļ�������ʾ��������, �� /START �������ṩ��ֵ���ᰴѡ�����ʾ�����������ļ������Ƚϡ����, �����ָ��
/COLLATING=STROKE, �ļ������ıʻ�����ֵ�ͻ���бȽ�,�Ծ�����Щ�ļ�����Ҫ��ʾ��������������˵����ν��С�
HMAIL> directory/folder/collating=stroke/start=��
�� DISK$USER:[USER]MAIL.MAI;1 �е��ļ����б�
HMAIL>directory/folder/collating=radical/start=��
�� DISK$USER:[USER]MAIL.MAI;1 �е��ļ����б�
HMAIL> directory/folder/collating=ascii/start=��
�� HMAIL ��, ����� HTPU ��ΪĬ�ϱ༭����������ʹ�� SET EDITOR ��������ѡ��ı༭������ȡ����Ĭ�ϡ�����,�����������������Ĭ�ϱ༭�������ó������ı༭����:
HMAIL> set editor [�����༭����]2
�������� HTPU �� HEVE ���ó�������ԡ�
HTPU �� HEVE ��ǿ DECTPU �� EVE �Ĺ��ܣ���֧�ֺ����ı��༭�� HEDT ���ܡ����ֹ��ó����֧���ַ���Ԫ�ն� (CCT) �û��ӿ�, Ҳ֧�� DECwindows Motif/Hanzi �û��ӿڡ�
HTPU/HEVE �� DECTPU/EVE Ϊ����, ��������ɣ��� HTPU (Hanzi Text Processing Utility) �� HEVE (Hanzi Extensible Versatile Editor)��HEVE ͨ�� HTPU ������̵��ú����ı������Ĺ��ܡ�
Ҫʹ�� CCT �ӿڵ��� HTPU, ���� HEVE ��ΪĬ�ϱ༭����, ����ʹ�����µ�����:
��Ҳ�������¶���һ����������Ӷ����̵�������:
Ҫʹ�� DECwindows Motif/Hanzi �ӿڵ��� HTPU, ���� HEVE ��ΪĬ�ϱ༭����, ����ʹ�����µ�����:
$ SET DISPLAY/CREATE/NODE=<���Ĺ���վ�Ľڵ���>
һ������ HEVE, ���ɰ����̼������ı�����Ҳ����ʹ�� HEVE �����Ԥ���幦�ܼ����ı����б༭�� �� 9-1 �г���ЩԤ���幦�ܼ���
�й� HEVE �������������, �ɲ��ġ�HEVE �û��ֲᡷ, ���� HEVE �� ���� <DO> ��, ���� HELP ���
HTPU �ṩһ��������̼��ɵ��õĽӿڣ����û����ƺ��ֱ༭���������Է��� HTPU Ĭ�ϱ༭���� HEVE, ֻ���� HTPU ���Լ���������̱�д�༭����, �����ɵ��ýӿ���Ӧ�ó����е��� HTPU��
��֮ DECTPU, HTPU ��ǿ�Ĺ��ܰ�����
�й�һ�����µĻ��ĵ�������̵����飬�ɲ��ġ�HTPU �� HEVE �û��ο��ֲᡷ���й� DECTPU ������̵����飬�ɲ��ġ�DEC Text Processing Utility Reference Manual������Guide to the DEC Text Processing Utility������ HTPU ���ԡ�
HTPU �ɵ��ýӿڵ����飬�ɲ��ı��ֲḽ¼ B.4���й� DECTPU �ɵ��ýӿڵ����飬����ġ�OpenVMS Utility Routines Manual���� 14 �¡�
HEVE �� HTPU ���Լ��������Ϊ���������Ա༭�����ַ��� ASCII �ַ���HEVE ֧�� EVE �����й���3�������������书�ܣ�
�й� HEVE ר�е�����ɲ��ġ�HTPU �� HEVE �û��ο��ֲᡷ���й� EVE ������, �ɲ��ġ�Extensible Versatile Editor Reference Manual����
HDUMP �� DUMP �ĺ��ְ汾, ����������ʾ�ʹ�ӡ DEC �����ַ������ļ�����, ��ǿ�� DUMP ���ó���
HDUMP �� DUMP ����Ҫ�������� HDUMP ������ȷ��ʾ˫�ֽں����ַ�����һ����ֻʣ��һ���ֽڶ�����������һ��˫�� DUMP �㲻�ܽ�����ȷ����, DUMP ֻ��Ѹú��ֵĵ�һ�ֽڷ�����ĩ,�ѵڶ��ֽ�ж������һ����, ������ɴ�������Ȼ��,HDUMP �ɰѸú��ֵĵ�һ���ڶ��ֽ�һͬ�Ƶ���һж������,����ʾ�ֶε������ǰ��ʾ���ӡһ�� ASCII �ַ�λ��
�������Ͽɺ��ַ�Χ���˫�ֽڴ�����Ծ�� (.) ��ʾ���ӡ��
���е��������ʾ��� DUMP ����ͬ��
�����ģţü��������˾�绰: 3-7315211
����DEC���������˾�绰: 3-7315211
Hdump of file WRKD$:[HANZI.SRC]HANZI.DAT;2 on 4-MAR-1991 15:16:48.94
File ID (3210,43,0) End of file block 1 / Allocated 3
Record number 1 (00000001), 39 (0027) bytes
ABBE3CB C6BCC3A3 C5A3C4A3 FAB9C0C3 �����ģţü���� 000000
2D33BAA3 B0BBE7B5 BECBABB9 DECFD0D3 ����˾�绰:3- 000010
313132 35313337 7315211..........000020
Record number 2 (00000002), 36 (0024) bytes
CFD0D3FA BBE3CBC6 BC434544 FAB9C0C3 ����DEC�������000000
���������ʽ�еĺ������ں�ʱ�����֧�֡������к������Ա���Ԥ�������ں�ʱ�������ʽ��ϵͳ���û���������Ӧ���躺�����ں�ʱ�������ʽ���� DCL ���� DIR �Լ� DCL ���ó��� MAIL �� HMAIL ��ʹ�á�����,�û��ڶ����Լ����û��������ں�ʱ�����뼰�����ʽʱ,����ʹ�ú������Ա�����Щ���ں�ʱ�����뼰�����ʽ������ OpenVMS RTL �����ں�ʱ��������г���ʹ�á��й����ں�ʱ��������г������÷�����������ġ�VMS RTL Library (LIB$) Manual����
�ú�������ʱ��ǰ, ϵͳ���� (���� CMEXEC��SYSNAM �� SYSPRV ��Ȩ���û�) ����ִ��������� SYS$MANAGER:LIB$DT_STARTUP.COM, �Ա�Ϊ����ʱ�䶨����������ʽ(����Ԥ���庺�������ʽ)������,Ҳ�ɶ��庺������ʱ�䵥Ԫ����������:
$ ! Define Hanzi output formats and date and time elements
�±�չʾԤ���庺������ʱ�������ʽ���й�ʹ�õ������������������ġ�VMS RTL Library (LIB$) Manual����
�������Ա��ɶ�������������Щ�����ɰ� 11.6 �ڵ��������û����������ʽ��ʹ�á��±��г���Щ���������ο�:
|
"����һ", "���ڶ�","������","������", "������","������", "������" |
||
|
"һ��", "����","����", "����"," ����", "����", "����", "����", "����", "ʮ��","ʮһ��", "ʮ����" |
||
ҪΪ���ڻ�ʱ��,�����ں�ʱ������ѡ��һ���ض��ĺ��ָ�ʽ,�û�����ʹ�� 11.3 �ڶ�������������� LIB$DT_FORMAT ����������:
$ DEFINE LIB$DT_FORMAT LIB$DATE_FORMAT_042,LIB$TIME_FORMAT_021
�������������Ĵ��������������Ĵ�����������ʹ������ָ���ĸ�ʽ������ں���һ���ո�, ֮������ָ����ʽ��ʾ��ʱ��,������ʾ:
�û���ʹ���Լ���ִ��̬�����Ժ�������������˵������ʽ������:
$ DEFINE/EXEC/TABLE=LNM$DT_FORMAT_TABLELIB$DATE_FORMAT_601 -
$ DEFINE/EXEC/TABLE=LNM$DT_FORMAT_TABLE LIB$TIME_FORMAT_601 -
������Ҫ�ĸ�ʽ��,�û�����������������ʹ����Щ��ʽ:
$ DEFINE LIB$DT_FORMAT LIB$DATE_FORMAT_601,LIB$TIME_FORMAT_601
ҪΪ����ʱ������ѡ��һ���ض��ĺ��ָ�ʽ�Թ�Ӧ��,�û����붨�� LIB$DT_INPUT_FORMAT ������LIB$DT_INPUT_FORMAT �ĵ�Ч�������� 11.4 ����������Ԥ���庺�����Ա��е��������
$ DEFINE LIB$DT_FORMAT LIB$DATE_FORMAT_043,LIB$TIME_FORMAT_021
1 NODEA:SYSTEM 1991��11��16�� ������ ������
#1 1991��11��16�� ������ ����11ʱ20��53�� MAIL
$ DEFINE LIB$DT_FORMAT LIB$DATE_FORMAT_043,LIB$TIME_FORMAT_021
������: 1991��11��17�� ������ ���� 6��35��25��
����: 1991��11��17�� ������ ���� 6��35��28�� (1)
�ļ����� : ����: 3, ��չ: 0,ȫ�ֻ������: 0, û�а汾����
��¼����: Carriage return carriage control
�ļ�����: System:RWED, Owner:RWED,Group:RE, World:
TEST.DAT;1 1991��11��17�� ������ ���� 6ʱ35��25��
TEST1.DAT;1 1991��11��17�� ������ ���� 6ʱ36��19��
TEST2.DAT;1 1991��11��17�� ������ ����6ʱ36��22��
TEST3.DAT;1 1991��11��17�� ������ ���� 6ʱ36��26��
int lib$convert_date_string();
unsigned int quadtime[2]; /*quadword to store time */
unsigned char instr[40]; /*input date time buffer */
unsigned char outstr[40]; /*output date time buffer*/
struct dsc$descriptor_s indate = /*input descriptor */
{ 40, DSC$K_DTYPE_T, DSC$K_CLASS_S, instr };
struct dsc$descriptor_s outdate = /*output descriptor */
{ 40, DSC$K_DTYPE_T, DSC$K_CLASS_S, outstr };
outdate.dsc$a_pointer = outstr;
/* convert date time from input format to quadword storage*/
lib$convert_date_string(&indate,quadtime);
/* convert date time from quadword to output format */
lib$format_date_time(&outdate,quadtime);
printf("Output date time: %40.40s \n",outstr);
$ DEFINE LIB$DT_FORMAT LIB$DATE_FORMAT_043, LIB$TIME_FORMAT_021
$ DEFINE LIB$DT_INPUT_FORMAT -
_$ "!Y4��!MNB��!DB�� !MIU!HB2ʱ!MB��!SB.!C2��"
Input date time:1991��10��11�� ����2ʱ16��26.02��
Output date time:1991��10��11�� ������ ����2ʱ16��26��
$ DEFINE LIB$DT_INPUT_FORMAT "!Y4��!MAU��!DB�� !HB4ʱ!MB��!SB.!C2��"
Input date time: 1991��ʮ��11�� 17ʱ12��22.02��
OpenVMS ��������һ�����ŵ����������ǵ����û�ģʽ�������ѡ����������֧���ַ���Ԫ�û������ͼ�� (DECwindows Motif) �û���������� OpenVMS ������Եķ��ŵ��ԡ��������û��������ڶ�֧�� DEC �����ַ������������ʾ���ڳ��������Դ����ע�ͻ� OpenVMS ������������Ϣ�еĺ����ַ����ܹ���ȷ��ʾ��
|
OpenVMS ������ʹ�� XPG4 ���ʻ�ģ��ʵ�ֶ� DEC �����ַ�����֧�֡���Ҫ��һ�� DEC �����ַ����� XPG4 �ֳ����ݿ⡣����������ͬ OpenVMS һ���е� OpenVMS 118n ���漯���ҵ�����ֳ����ݿ⡣ |
��������������� OpenVMS ���������ַ���Ԫ�û������ DECwindows Motif �û�������ʹ�ú����ַ���
OpenVMS ���������ַ���Ԫ�û�����һ��ʹ�ú��� SMG �� DEC C �� XPG4 ���ػ����ó�����֧�� DEC �����ַ�����Ҫ֧���������붨����������:
����������� OpenVMS ����������֧����Ļģʽ�� SMG ����ӳ������ơ�Ҫ����֧�� DEC �����ַ��������������������:
$ DEFINE/JOB DBG$SMGSHR HSMGSHR
����������庺�� SMG ֧�ֵ�Ĭ���ַ�����Ҫ����֧�� DEC �����ַ��������������������:
$ DEFINE/JOB SMG$DEFAULT_CHARACTER_SET HANZI
�������Ϊ DEC C �� XPG4 ���ػ����ó��������ʱ��������ֳ�����Ĭ�ϵ��ֳ����á�Ҫ������ OpenVMS ��������֧�� DEC �����ַ��������������������:
OpenVMS �������� DECwindows Motif �û����������ʾ DEC �����ַ����е��ַ�����Ŀ¼ DECW$SYSTEM_DEFAULT ��DECW$USER_DEFAULTS �еĵ�������Դ�ļ� VMSDEBUG.DAT ����Ϊÿ��������������ȷָ�����塣
�� VMSDEBUG.DAT ��, DebugDefault.font ��ԴΪ���е���������ָ��һ��Ĭ�����塣ÿ������Ҳ����ʹ����Ĭ���ַ��IJ�ͬ���塣Ҫ֪���飬����� VMSDEBUG.DAT �ļ���
Ҫ������ OpenVMS ������������֧�� DEC �����ַ������ô��ڱ���ʹ�� DEC �����ַ������塣��ͨ�����·���֮һָ�������壺
OpenVMS/Hanzi ���û���ע�͡��ַ����ַ���������ʹ�ú���,���ڱ���������ܴ����������ֵ����뼰������ݡ�
�����г�һЩ�����һ����������ʹ�ú��ֵ�����������Щ��������Ҳ���� OpenVMS/Hanzi ϵͳ�� HSY$EXAMPLE Ŀ¼���档
VAX_MACRO = 1 ;If you want to compile this example
;with MACRO-32, then the VAX-MACRO symbol
;must be set to 0. Otherwise, you may
;encounter a problem during compilation.
DATA1: .ASCID /VAX MACRO �뺺�ֹ���/
DATA2: STRING <VAX MACRO �� MACRO ʹ�ú���>
.ENTRY SAMPLE, ^m<> ; ��ע����ʹ�ú���.
sample:proc options (main); /* ��ע����ʹ�ú���*/
put list ('VAX PL/I �뺺�ֹ���');
put skip edit ('��������: ') (a);
HSYSHR ������ OpenVMS/Hanzi ϵͳ�ĺ��ִ�������ʱ�����, ���Ǹ�ͨ������ʱ���, �����ṩ�������ִ������ܵ����г���
�ڴ�ϵͳ���й�������������������Ҫ֪����Щ���г���Ĺ��ܡ����ø�ʽ������:
����ʱ�������ڿɹ���ӳ��� HSYIMGLIB.OLB ��,������ OpenVMS/Hanzi ��֧�ֵ��κ�һ�ֱ�����������ÿ�Ĺ��ܡ�Ҫ�ѳ���������ʱ�������,����:
$ LINK PROGRAM, SYS$LIBRARY:HSYIMGLIB/LIB
�й�����, ����ġ�OpenVMS/Hanzi RTL Chinese Processing (HSY$) Manual����
$ TYPE HSY$EXAMPLE:SAMPLE_HSYSHR.C
This is a C language example to demostrate the
ability of the HSY$ facility of the OpenVMS
Run Time Library, HSYSHR. The program
accepts an input file from the command line and
formats the text within it in the following ways:
- Left margin = 0, Right margin = 40
- Convert all half form ASCII characters to their full
- Remove leading and trailing blanks of each
- Remove all embedded controls or space characters.
typedef unsigned char mstr; /*Local language string type */
typedef unsigned char *mstr_p;/* Pointer type to local */
typedef unsigned long mchar; /*Multi-byte character type*/
#define INPUT_STR_LEN 128 /* Max length of input line*/
#define OUTPUT_STR_LEN 128*2 /* Max length of output line */
#define MARGIN 40 /* Width of output text */
#define SUCCESS 1 /* Successful call */
#define FAILURE 0 /* Unsuccessful call */
#define SPACE 0x00000020 /* Space character in
extern HSY$IS_VALID(), /* External HSY$ routines to */
HSY$CH_RNEXT(),HSY$CH_WNEXT(),/* used */
HSY$CH_SIZE(), HSY$CH_NCHAR(), HSY$CH_NBYTE(),
HSY$CH_TRIM(), HSY$SKPC(), HSY$TRA_ROM_FULL();
FILE *fdin, /* Input file descriptor */
*fdout; /* Output file descriptor */
int line_length; /* Remaining number of bytes */
/* of the current output line*/
This routine will accept an input buffer and its length
in number of characters, and write the string to the
output file at 40 bytes per line. A blank line is printed
int write_text(buffer, buf_len)
mstr_p buffer; /* Output buffer */
int buf_len; /* Buffer length in number */
int char_size, /* Character size in bytes */
offset, /* Offset of input buffer */
mchar curr_char; /* Current multi-byte char */
mstr_p buf_ptr; /* Pointer to buffer */
if (buffer == NULL){ /* Empty line, next paragraph*/
if (line_length != EMPTY) fprintf(fdout,"\n");
offset=EMPTY;buf_ptr=buffer;/*Initialize for the loop */
for (i= EMPTY; i < buf_len; i++) {
curr_char = HSY$CH_RNEXT(&buf_ptr);
char_size = HSY$CH_SIZE(curr_char);
/* Calculate the size of the */
if (line_length < char_size) {
for (j=0; j < char_size; j++){
/* Put a multi-byte character*/
fputc(buffer[offset++], fdout);
This routine accepts an input string, removes its
railing and leading blanks, converts all half form ASCII
to their full forms and places the
converted string into a buffer which will be written to
mstr in_str[]; /* Zero terminated input */
mstr buffer[OUTPUT_STR_LEN];/* Output buffer */
mstr_p str_ptr, /* Pointer to source string */
dst_ptr; /* Pointer to dest. string */
mchar curr_char; /* Current multi-byte char */
int status, /* Return status */
pos, /* Position of trimmed string*/
charsofar, /* Character processed so far*/
noofchar, /* No. of characters and */
noofbytes; /* bytes in a string. */
if (!(str_ptr = HSY$SKPC(SPACE, in_str, strlen(in_str)-1)))
return write_text(NULL,EMPTY);/* Skip leading blanks */
pos = HSY$TRIM(str_ptr, strlen(str_ptr)-1);
if (!(HSY$TRA_ROM_FULL(str_ptr, pos, buffer, OUTPUT_STR_LEN, &noofbytes)))
return FAILURE; /* Convert to full form */
noofchar = HSY$CH_NCHAR(buffer,noofbytes);
str_ptr = dst_ptr = buffer;/* Initialize for the loop */
curr_char = HSY$CH_RNEXT(&str_ptr);
if (HSY$IS_VALID (curr_char)) {
/* Test for valid multi-byte */
HSY$CH_WNEXT(curr_char, &dst_ptr);
/* character and write to the*/
charsofar ++ ; /* destination. */
write_text(buffer, charsofar);
/* Write the text out to file*/
This main program check for a valid command line, open all
necessary files and call the appropriate routine to
mstr in_str[INPUT_STR_LEN]; /* Input line */
printf("Usage: $ FORMAT <input_file> <output_file>\n");
if ((fdin = fopen(argv[1], "r")) == NULL) {
printf("Error: Cannot open input file %s.\n", argv[1]);
if ((fdout = fopen(argv[2],"w")) == NULL) {
printf("Error: Cannot open output file %s.\n", argv[2]);
while (fgets(in_str, INPUT_STR_LEN, fdin) != NULL)
printf("Information: Processing error.\n");
printf("Information: Finish Processing.\n");
$ LINK SAMPLE_HSYSHR, SYS$LIBRARY:HSYIMGLIB/LIB
OpenVMS/Hanzi ϵͳ����������Ļ��������ʱ��� HSMGSHR ������һ�����г������,��Щ���г�����������Ӱ����Ļ����ơ����ɺͼ�����Ļӳ��
HSMGSHR �ṩ������Ҫ����:ʹ�������ն�����ת����Ӱ��; ���ڹ�����Ļӳ��
������ OpenVMS/Hanzi ��֧�ֵ��κ�һ�ֱ�����������ÿ�ܡ�Ҫ�ѳ����� HSMGSHR ����, ����:
$ LINK PROGRAM, SYS$INPUT/OPTION
�й�����, ����ġ�OpenVMS RTL Chinese Screen Management (SMG$) Manual����
��Щ���г���ʹ���ܰ������ϲ��������뵽����Ӧ����ȥ�����������ݼ�¼������Щ�������ݼ�¼�����ϲ�,Ȼ���ٴ���֮��
���µ��û��ɵ������г��������ϲ�����ʹ�á��й�����,
����ġ�OpenVMS Utility Routine Reference Manual����
�κ�֧�� OpenVMS ���̵��ü����������������Զ��ɵ������ϵ����г���Ϊ��ʹ�� OpenVMS/Hanzi �� SORT �� MERGE �ɵ��ó���Ӧ�ó������ʹ������������������ʱ�������:
���г����ú��ִ�б����Ĺ���,Ȼ���ͻؿ��Ƶ����ó���ȥ��
���еĴ�����������������,�����еı���������ַ���͡���Щ��������λ�ò���,�û��ɰ�ֵ����һ������ָ����ѡ���������ó������һ�������б�����ʡ���������OpenVMS Utility Routine Reference Manual����
�û��������е�α����������ָ��������������,��Щα����������ͨ�÷��� (universal symbols) ����ʽ���ֹ��û�ʹ�á�
��Щα��������Ӧ��ָ��Ϊ�ؼ��ֵ��������͡�
�����ɵ������г����ڴ�����������ʱ�ͻص�״̬���봦�� ASCII ����ʱ�ͻص�״̬����ͬ���й�����,����ġ�OpenVMS Utility Routine Reference Manual����
�û��ɰ������������ļ�����¼����ʽ�ύ�ɵ������г������ij�����������ʹ���ļ��ӿڡ������ij���һ���ύһ����¼��Ȼ��һ�ν���һ���������¼ʱ,
�û�Ҫ����ļ��ӿ����¼�ӿ�, ��������ʱ�ύ�ļ�,�������ʱ�����������¼����һ�����еķ�����������ʱ�ͷż�¼,�������ʱ���������¼д��һ���ļ��С����������ӿ������������и��������ԡ�
$ TYPE HSY$EXAMPLE:SAMPLE_SORT1.FOR
C The following FORTRAN program sorts the records in the file
C POET.DAT and creates an output file named EXAM1OUT.DAT.
C All the records in the input file are sorted in Pinyin
C collating sequence based on the first 12 bytes, that is,
C the first 6 Chinese characters in each record.
DATA IN_FILE, OUT_FILE /'POET.DAT','EXAM1OUT.DAT'/
KEYBUFF(1) = 1 ! Number of KEY
KEYBUFF(2) = %LOC(SOR$K_SEQ_PINYIN)
KEYBUFF(3) = 0 ! Ascending sort
KEYBUFF(5) = 2 ! Size in bytes
STATUS = SOR$PASS_FILES(IN_FILE, OUT_FILE)
$ TYPE HSY$EXAMPLE:SAMPLE_SORT2.FOR
C This is a FORTRAN language example calling sort routines using
C multiple collating sequences.
C This program sorts data with file interface on input and record
C interface on output.Two collating sequences are specified here,
C the first being the number of stroke count with ascending sort
C order and the second being the radical sequence with descending
C Define external functions and data and initialize
CHARACTER*9 INPUTNAME ! Input file name
INTEGER*2 KEYBUF(9) ! Key definition buffer
EXTERNAL SOR$K_SEQ_STROKE ! Stroke collating sequence
KEYBUF(2) = %LOC(SOR$K_SEQ_STROKE) ! Primary key STROKE
KEYBUF(6) = %LOC(SOR$K_SEQ_RADICAL)
ISTATUS = SOR$PASS_FILES(INPUTNAME)
C Initialize the work areas and keys
ISTATUS = SOR$BEGIN_SORT(KEYBUF,,,,,,SRTTYPE,%REF(3))
C Now retrieve the individual records and display them.
5 ISTATUS = SOR$RETURN_REC(RECBUF)
ISTATUS = LIB$PUT_OUTPUT(RECBUF)
6 IF (ISTATUS .EQ. %LOC(SS$_ENDOFFILE)) GOTO 7
$ TYPE HSY$EXAMPLE:SAMPLE_MERGE.C
/* This is a C language example.
This program merges two input files into one output file.
The key is starting from the first byte of the record
(offset zero byte) of size two bytes(i.e. 1 Chinese
character).It also checks if the input files sequence
struct DESCRIPTOR { int leng ;
char infile1[] = "EXAM31.DAT" ,
inptr1 = {strlen(infile1) ,infile1},
inptr2 = {strlen(infile2) ,infile2},
outptr = {strlen(outfile) ,outfile};
key[1] = SOR$K_SEQ_PINYIN ; /* pinyin */
option = SOR$M_SEQ_CHECK; /* check input sequence */
if(!((status=sor$pass_files(&inptr1,&outptr))
if(!((status=sor$pass_files(&inptr2))
���ڿɵ��� HTPU ���г����ϵ,���ɴ��κγ������Լ�Ӧ�ó����е��� HTPU�����ɴ����κ�ʹ�� OpenVMS ���̵��ü��������������ɵ��õı�����Ա�д�ij����е��� HTPU�� ��Ҳ���Դ� OpenVMS ���ó����� HMAIL �е��� HTPU�� �ɵ��� HTPU ���г����������ڳ�����ʹ�ú����ı��������ܡ�
HTPU ֧�� DECTPU ��֧�ֵ�ͬһ�ɵ��ýӿ�,���ɵ��ýӿں�ȫ��ɵ��ýӿڡ��й� DECTPU �ɵ��ýӿڵ�����, ����ġ�VMS Utility Routines Manual���� 14 �¡�
�����֮��HTPU �ɵ��ýӿں� DECTPU �ɵ��ýӿڵķֱ����£�
�������� BLISS ��д����������,��ʹ��ȫ��ɵ��ýӿڵ��� HTPU:
! Example program of using HTPU full callable interface.
! 2. $ LINK EXAMPLE,SYS$INPUT/OPTION
! 3. $ DEFINE HTPU$TESTING <your directory>
ADDRESSING_MODE (EXTERNAL = GENERAL)) =
! To test the callable interface of HTPUSHR
TEST_USER_ARG = %X'F0'; !an arbitrary pattern
test_callback, ! Callback for tpu$initialize
test_call_user, ! Call user routine
tpu$fileio, ! HTPU file routine
tpu$message, ! Displays HTPU message
tpu$cliparse, ! HTPU CLI parser
tpu$initialize, ! Initialize HTPU
tpu$execute_inifile, ! Execute initial commands
tpu$execute_command, ! Execute HTPU statements
tpu$control, ! HTPU main control loop
callback_bpv : BLOCK [8, BYTE],
! Setup the callback procedure
$test_set_bpv (callback_bpv, test_callback);
!Set the user argument for test_callback,but ignored there
!Initialize HTPU. Initialization options are specified in
status = tpu$initialize (callback_bpv, .user_arg);
! Set up the default section file
status = tpu$execute_inifile();
! Finally, we clean up the HTPU and then return
cleanup_flag = tpu$m_delete_context;
RETURN tpu$cleanup (cleanup_flag);
ROUTINE test_callback (user_arg) =
! Sets up the item list for tpu$initialize
call_user_bpv : BLOCK [8, BYTE],
$test_set_bpv (fileio_bpv, tpu$fileio);
$test_set_bpv (call_user_bpv, test_call_user);
! Calls tpu$cliparse to construct item list for
! passing it tpu$fileio as the fileio routine and
! test_call_user as the call_user routine
$DESCRIPTOR ('HTPU htpu$testing:test.txt'),
ROUTINE test_call_user (int_param,
str_out : REF BLOCK [,BYTE]) =
! It simply prints out the integer parameter int_param
! and the string parameter str_param by means of tpu$message
buffer_desc : BLOCK [8, BYTE],
! Form a fixed-length string descriptor
buffer_desc [DSC$W_LENGTH] = 80;
buffer_desc [DSC$B_DTYPE] = DSC$K_DTYPE_T;
buffer_desc [DSC$B_CLASS] = DSC$K_CLASS_S;
buffer_desc [DSC$A_POINTER] = buffer;
! Construct the ini_param message and print it out
status = $FAO ($DESCRIPTOR('Integer: !UL'),buffer_len,
buffer_desc [DSC$W_LENGTH] = .buffer_len;
status = tpu$message (buffer_desc);
buffer_desc [DSC$W_LENGTH] = 80;
! Construct the str_param message and print it out
status = $FAO ($DESCRIPTOR('String: !AF'), buffer_len,
buffer_desc, .str_param [DSC$W_LENGTH],
buffer_desc [DSC$W_LENGTH] = .buffer_len;
status = tpu$message (buffer_desc);
buffer_desc [DSC$W_LENGTH] = 80;
! We need to use lib$sget1_dd to allocate the memory
! for the return string since TPU uses lib$sfree1_dd
! to free our string when it needs to.
str_out_len = %CHARCOUNT(%STRING('Success'));
status = lib$sget1_dd (str_out_len, str_out [0,0,0,0]);
! Perform editing to the buffer
status=tpu$execute_command ($DESCRIPTOR (command));
! It first copies two lines to the MAIN buffer
$test_execute ('COPY_TEXT("This is the first statement");
$test_execute('COPY_TEXT("This is the second statement");