Software > OpenVMS Systems > Documentation > 731final > 4506 HP OpenVMS Systems Documentation |
Guide to OpenVMS File Applications
3.5.1.2 Primary Index StructureThe primary index structure consists of the file's data records and a key pathway based on the primary key (key 0). The base of a primary index structure is the data records themselves, arranged sequentially according to the primary key value. The data records are called level 0 of the index structure. The data records are grouped into buckets, which is the I/O unit for indexed files. Because the records are arranged according to their primary key values, no other record in the bucket has a higher key value than the last record in that bucket. This high key value, along with a pointer to the data bucket, is copied to an index record on the next level of the index structure, known as level 1. The index records are also placed in buckets. The last index record in a bucket itself has the high key value for its bucket; this high key value is then copied to an index record on the next higher level. This process continues until all of the index records on a level fit into one bucket. This level is then known as the root level for that index structure. Figure 3-1 is a diagram of an index structure. Figure 3-2 illustrates a primary index structure. (For simplicity, the records are assumed to be uncompressed, and the contents of the data records are not shown.) The records are 132 bytes long (including overhead), with a primary key field of 6 bytes. Bucket size is one block, which means that each bucket on Level 0 can contain three records. You calculate the number of records per bucket as shown by the following algorithm: 
Figure 3-1 RMS Index Structure  Because the key size is small and the database in this example consists
of only 27 records, the index records can all fit in one bucket on
level 1. The index records in this example are 6 bytes long. Each index
record has one byte of control information. In this example, the size
of the pointers is 2 bytes per index record, for a total index record
size of 9 bytes. You calculate the number of records per bucket in this
case as follows:
Because the key size is small and the database in this example consists
of only 27 records, the index records can all fit in one bucket on
level 1. The index records in this example are 6 bytes long. Each index
record has one byte of control information. In this example, the size
of the pointers is 2 bytes per index record, for a total index record
size of 9 bytes. You calculate the number of records per bucket in this
case as follows:
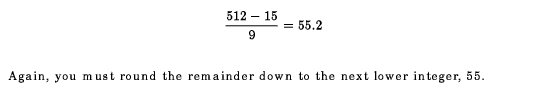
Figure 3-2 Primary Index Structure 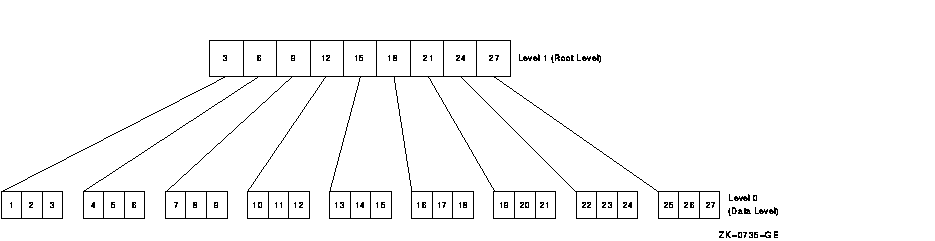 To read the record with the primary key 14, RMS begins by scanning the
root level bucket, looking for the first index record with a key value
greater than or equal to 14. This record is the index record with key
15. The index record contains a pointer to the level 0 data bucket that
contains the records with the keys 13, 14, and 15. Scanning that
bucket, RMS finds the record (see Figure 3-3).
To read the record with the primary key 14, RMS begins by scanning the
root level bucket, looking for the first index record with a key value
greater than or equal to 14. This record is the index record with key
15. The index record contains a pointer to the level 0 data bucket that
contains the records with the keys 13, 14, and 15. Scanning that
bucket, RMS finds the record (see Figure 3-3).
Figure 3-3 Finding the Record with Key 14 
3.5.1.3 Alternate Index StructureAlternate indexes (also referred to as secondary indexes) provide your program with alternate record processing. If you have one or more alternate indexes, you can process data records using any of the alternate keys in addition to processing data with the primary key. Note that a file with alternate indexes does require additional disk space. The alternate index structure is similar to the primary index structure except that, instead of containing data records, alternate indexes contain secondary index data records (SIDRs). An SIDR includes an alternate key value from a data record in the primary index and one or more pointers to data records in the primary index. (SIDRs have pointers to more than one record only if you allow duplicate keys and there are duplicate key values in the database.) You do not need an SIDR for every data record in the database. If a variable-length record is not long enough to contain a given alternate key, an SIDR is not created. For example, if you define an alternate key field to be bytes 10 through 20 and you insert a 15-byte record, no SIDR is created in that alternate index structure. When you create a file, you can use null key values to improve performance for programs that use alternate keys. When a secondary index has relatively few entries, performance may diminish because RMS tries to treat the null entries (typically blank keys) as duplicates. The resultant duplicate-key processing is unnecessary and can be avoided by assigning a null key value for the index. By using a null key value, you minimize the list of duplicates. This can improve performance when you insert records because the null key entries do not get processed as index entries. Note that when you sequentially access records using null key processing, null records are not processed. If you use the string data type, RMS uses the ASCII null character as the default null key value. However, you can specify any character as the null value. If you use numeric keys, RMS uses zero (0) as the null value. 3.5.1.4 RecordsRecords in an indexed file can be fixed-length records or variable-length records. Fixed-length records begin with a record header. Variable-length records include a record header followed by a 2-byte count field that contains the number of data bytes in the record. Unlike variable-length records in relative files, each variable-length record in an indexed file requires only enough space for the record. See Table 2-2 for more information on record overhead. Records cannot span bucket boundaries. For Prolog 3 files, the maximum record size is 32,224 bytes. For Prolog 1 files and Prolog 2 files, the maximum length for a fixed-length record is 32,234 bytes; the maximum length for a variable-length record is 32,232 bytes. Note that when you specify a record length for a Prolog 3 file that is greater than the maximum record length, RMS automatically converts the file to a Prolog 1 or Prolog 2 file. Record length should reflect application requirements. There is no advantage to using a record length that is based on the number of bytes in a bucket. The value of the primary key must be contained within the records. The records can contain either a valid key field value for the alternate keys or, if you specify that null keys are allowed, a field of null characters. 3.5.1.5 KeysA key is a record field that identifies the record to help you retrieve the record. There are two types of keys---primary keys and alternate keys. Data records are filed in the order of their primary key. The most time-efficient value for primary keys is a unique value that begins at byte 0 of the record. You can allow duplicate keys in the primary index, but duplicate keys may slow performance. The primary key and alternate keys can be character strings or numerical values. Key type is specified by the FDL attribute KEY TYPE. If it is not possible to put the records into the file in order of their primary key, you should specify that the buckets not be filled completely when the file is loaded. If you attempt to write a record to a full bucket, a bucket split occurs. RMS keeps half of the records in the original bucket and moves the other records to the newly created bucket. Each time a record moves to a new bucket, it leaves behind a forwarding pointer called a record reference vector (RRV). You should avoid bucket splits because they use additional disk space and CPU time. An extra I/O operation is required to access a record in a split bucket when the program accesses a record by an alternate key or by RFA. Alternate keys have a direct impact on I/O operations, CPU time, and disk space. The number of I/O operations and the CPU time required for Put, Update, and Delete operations are directly proportional to the number of keys. For example, inserting a record with a primary key and three alternate keys takes approximately four times longer than inserting a record with only a primary key. To update the value of an alternate key, you have to traverse the alternate index structure twice, and bucket splits are more likely to occur. Randomly accessing an alternate key generally requires an extra I/O operation over a comparable access by the primary key, and extra disk space is required to store each alternate index structure. Alternate keys are more likely than primary keys to have duplicate values. For example, the zip code is a common alternate key. However, allowing many duplicate values can have a performance cost. Duplicate values can cause clustered record or pointer insertions in data buckets, long sequential searches, a large number of I/O operations, and loss of physical contiguity due to continuation buckets (especially for the primary key). Where possible, you should validate record keys before inserting the record, especially when you have primary and alternate keys. In general, as the number of keys increases, so does the time it takes to add and delete records from your file. If CPU time is a critical resource on your system, you should define as few keys as possible. If you are reading records in your file, the number of keys has relatively little impact on performance. 3.5.1.6 AreasAn area is a portion of an indexed file that RMS treats as a separate entity. You can divide an indexed file into separate areas where each area has its own bucket size, initial allocation, extension size, and volume positioning, just as if each area were a separate file. Using multiple areas has distinct advantages. However, if each area has a different bucket size, all buffers are as large as the largest bucket. If you use multiple areas, the file itself is probably not contiguous; however, you can make each area within the file contiguous by specifying the FDL attribute AREA CONTIGUOUS. To ensure that the area is created without error, use the AREA BEST_TRY_CONTIGUOUS attribute. When you separate key and data areas, you tend to keep related buckets close together, thereby decreasing disk seek time. You also minimize the number of disk-head movements for a series of operations. For example, if you have a dedicated multidisk volume set, you could place the data level of a file in an area on one disk and the index levels of the file in an area on a separate disk. Then there is little or no competition for the disk head on the disk that contains the index structures. One strategy is to allocate a separate area for level 0 of a primary index (the data level). These buckets are the only ones referenced when you access the records sequentially by their primary key, so keeping them in a separate area optimizes that type of operation. Do not allocate separate areas for level 1 of an index and the other index levels if the index has just one level. In such a case, you force RMS to create an additional level in the index structure. In most cases, you should allocate at least one area for each alternate index structure. By default, EDIT/FDL creates two areas in an indexed file for each index structure---one for the data level and one for all of the index levels. You can allocate up to 255 areas, so with most applications you can set up enough areas to handle all alternate index structures. It is possible to set up a separate area for each of the following:
Be sure to allocate sufficient space for each area and to specify area contiguity, because extending an area generally creates a noncontiguous area extent. The resulting noncontiguous extent may be anywhere on the disk, and you may lose the benefits of multiple areas. If you are using a single area for the file, you should allocate enough contiguous space at creation time for the entire file. If you plan to add data to the file later, you should allocate extra space using the FDL attribute FILE ALLOCATION. To ensure contiguous allocation, set the FDL attribute FILE CONTIGUOUS to YES. If you are using multiple areas, you should allocate each one by specifying a value for the FDL attribute AREA ALLOCATION. If the file is relatively small, or if you know that it needs to be extended, you do not have to use multiple areas. In such cases, it is more important to calculate the proper extension size. To specify multiple areas using an FDL file, you assign each area its own AREA primary attribute. The AREA primary attribute takes as an argument a number whose value identifies the area. Use the KEY attributes DATA_AREA, LEVEL1_INDEX_AREA, and INDEX_AREA to match each area specified with its index level. In the primary index structure, the primary attribute KEY must take the value 0. Within the KEY 0 section, you assign the DATA_AREA attribute the number which identifies the data record area. Then you associate the KEY LEVEL1_INDEX_AREA attribute with an AREA by assigning the appropriate area number to the LEVEL1_INDEX_AREA attribute. You also assign the appropriate area number to the INDEX_AREA attribute for the other index levels in the primary index structure. For each alternate index structure, you use the same attributes (DATA_AREA, LEVEL1_INDEX_AREA, INDEX_AREA) in another KEY primary attribute. In KEY sections that define alternate keys, the DATA_AREA is where RMS puts the SIDRs. 3.5.2 Optimizing File PerformanceThis section discusses adjustments in file design that can improve a file's performance. 3.5.2.1 Bucket SizeFor indexed files, the bucket size controls the number of levels in the index structure, which has the greatest impact on performance for most applications. You can specify the bucket size with the FDL attribute FILE BUCKET_SIZE or the control block fields FAB$B_BKS and XAB$B_BKZ. When you sequentially access files, large buckets are generally beneficial. For keyed access to index files, set the bucket size so that the number of index levels does not exceed four. In general, the smaller the bucket size, the deeper the tree structure. If you find that a small increase in bucket size eliminates one level, use a larger bucket size. At some point, however, the benefit of having fewer levels is offset by the cost of scanning through the larger buckets. As a rule, you should never increase bucket size unless the increase reduces the number of levels. For example, you may find that a bucket size of 4 or more yields an index with four levels, and a bucket size of 10 or more yields an index with three levels. In this case, you never want to specify a bucket size of 9 because that does not reduce the number of levels, and performance does not improve. In fact, such a specification could hurt performance because each I/O operation takes longer, yet the number of accesses remains the same. However, larger bucket sizes always improve performance if you are accessing the records sequentially by primary key because more records fit in a bucket. Conversely, with smaller buckets you have to search fewer keys. So if you can cache your whole structure (except for level 0), you can save a lot of time. Also, performance in this case is comparable to flat file design although add operations may take a little longer. You can decrease the depth of your index structure in two ways. First, you can increase the number of records per bucket by increasing the bucket size, increasing the fill factor, using compression, or decreasing the size of keys and records.
However, changing the bucket size also has disadvantages. Larger buckets use more buffer space in memory. And the number of records per bucket determines bucket search time, which directly affects CPU time. A larger fill factor decreases the room for growth in the file, so bucket splits may occur. Compression increases the record search time. Alternatively, you can reduce the index depth by decreasing the number of records in the file. If you are using multiple areas, you can set a different bucket size for each area. You should use different bucket sizes if you are performing random accesses of records in no predictable pattern and if the data records are large. Using different bucket sizes allows you to specify a smaller size for the index structures and SIDRs than for the primary data level. You can use the Edit/FDL utility to determine the optimum bucket size. Use the same bucket size for all areas if the data records are small or if the record accesses follow a clustered pattern, that is, if the records that you access have keys that are close in value. In general, increasing the bucket size increases other resources:
Conversely, decreasing the bucket size decreases the pages per bucket and the average number of keys searched while traversing the tree. 3.5.2.2 Fill FactorIf you know that the application makes random insertions into the database, you should reserve some space in the buckets when records are first loaded into the file. You can specify a fill factor from 50% to 100%. For example, a fill factor of 50% means that RMS writes records in only half of each bucket when the records are first loaded, leaving the remainder of the bucket empty for future write operations. This fill factor minimizes the number of bucket splits. The fill factor is set with the FDL attributes KEY DATA_FILL and KEY INDEX_FILL. The value assigned to both attributes should be the same. When you specify a fill factor, consider the following:
3.5.2.3 Number of BuffersAt run time, you can specify the number of buffers with the FDL attribute CONNECT MULTIBUFFER_COUNT, the control block field RAB$B_MBF, or the XAB$_MULTIBUFFER_COUNT XABITM. The number of buffers each application needs depends on the type of record access your application performs. The minimum number of buffers for indexed files is two. If the application performs sequential access on your database, two buffers are sufficient. More than two buffers for sequential access could actually degrade performance. During a sequential access, a given bucket is accessed as many times in a row as there are records in the bucket. After RMS has read the records in that bucket, the bucket is not referenced again. Therefore, it is unnecessary to cache extra buckets when accessing records sequentially. When you access indexed files randomly, RMS reads the index portion of the file to locate the record you want to process. RMS tries to keep the higher-level buckets of the index in memory; the buffers for the actual data buckets and the lower level index buckets tend to be reused first when other buckets need to be cached. Therefore, you should use as many buffers as your process working set can support so you can cache as many buckets as possible. When you access records sequentially, even after you have located the first record randomly, you should use a large bucket size. A small multibuffer count, such as the default of two buffers, is sufficient. If you process your data file with a combination of the above access modes, you should compromise on the recommended bucket sizes and number of buffers. When you add records to an indexed file, consider choosing the deferred-write option (FDL attribute FILE DEFERRED_WRITE; FAB$L_FOP field FAB$V_DFW). With this option, the buffer into which the records have been moved is not written to disk until the buffer is needed for other purposes, the Flush service is used, or until the file is closed. The deferred-write option, however, may cause records to be lost if a system crashes before RMS transfers the records to the disk. In general, you must consider several trade-offs when you set the number of buffers your application needs:
With indexed files, buckets (not blocks) are the units of transfer between the disk and memory. You specify the bucket size when you create the file, although you can change the bucket size of an existing file with the Convert utility (see Chapter 10). 3.5.2.4 Global BuffersIf several processes share the indexed file concurrently, you may want to specify that the file use global buffers. A global buffer is an I/O buffer that two or more processes can access. If two or more processes request the same information from a file, each process can use the global buffers instead of allocating its own. Only one copy of the buffers resides at any one time in memory although the buffers are charged against each process's working set size. The guideline for using global buffers is the same as the guideline for using local process I/O buffers. Global buffers only provide significant benefits if more than one process refers to the same bucket in the global cache. If bucket contention is high, I/O transfers can be minimized and performance improved. However, global buffers do not always improve performance. For example, multiple processes independently reading records and using sequential access are most apt to refer to separate buckets. In that case, bucket contention is low and the number of I/O transfers is not reduced, so global buffers do not improve performance.
|