Software > OpenVMS Systems > Documentation > 731final > 4506 HP OpenVMS Systems Documentation |
Guide to OpenVMS File Applications
8.4.2 Processing Relative FilesThe relative file organization permits greater program flexibility in performing record operations than the sequential organization. A program can read existing records from the file using sequential, random access by relative record number mode or random access by RFA mode. You can write new records either sequentially or randomly, as long as the intended record location (cell) does not already contain a record. You can also delete records. All record access modes for relative files allow you to establish the current-record position using the Find or Get service. After finding the record, RMS permits you to delete the record from the relative file. After the record is deleted, the empty cell becomes available for a new record. In addition, your program can update records anywhere in the file. For variable-length records, the Update service can modify the record length up to the maximum size specified when the file was created. When you insert a record into a relative file, the record is placed in a fixed cell within the file. A cell within a relative file can contain a record, can be vacant (never have contained a record), or can contain a deleted record. The following sections discuss the sequential and random access modes for relative files. 8.4.2.1 Sequential AccessFor relative files, the sequential access mode can be used to retrieve successive records in ascending record number. Vacant cells and cells that contain deleted records are skipped over automatically. 8.4.2.2 Random AccessYou can directly read a record within a relative file by specifying the appropriate relative record number. If you attempt to read from a nonexistent cell---that is, a vacant cell or a cell containing a deleted record---RMS returns an error message. To position the record stream at a particular cell, regardless of whether or not it contains a record, use the nonexistent-record option (FDL attribute CONNECT NONEXISTENT_RECORD), or set the RAB$V_NXR bit in the RAB$L_ROP field. You can use the forward search key options (equal-or-next-key and next-key) to directly access records in relative files, but the reverse search key options are not supported for relative files. The equal-or-next-key option (FDL attribute CONNECT KEY_GREATER_EQUAL) directs RMS to return a record having a record number equal to or greater than the specified record number. For example, when you specify record number 48, RMS returns record number 48. If RMS does not find record number 48, it returns the first record it encounters having a number greater than 48. The next-key option (FDL attribute CONNECT KEY_GREATER_THAN) directs RMS to return the record that has the next greater record number. For example, when you specify record number 48, RMS returns record number 49, if record 49 exists. You can also use random access mode to insert records into relative files. You can even overwrite cells that contain records by selecting the update-if option (FDL attribute CONNECT UPDATE_IF) or by directly setting the RAB$V_UIF bit in the RAB$L_ROP field. To access a relative file randomly by record number, your program must contain the relative record number in the RAB at symbolic offset RAB$L_KBF and the key length value 4 at symbolic offset RAB$B_KSZ. 8.4.3 Processing Indexed FilesIndexed files provide the most record-processing flexibility. Your program can read existing records from the file in sequential, random access by RFA mode or random access by key mode. RMS also allows you to write any number of new records into an indexed file if you do not violate a specified key constraint, such as not allowing duplicate key values. In random access by key mode, RMS provides two forward search key options for use with one of four match options (see Section 8.4.3.2). A reverse search key option permits reverse random access when used in combination with either of the two forward search key options.
Table 8-2 lists the search key types for each option combination. Note that three of the listed combinations are not supported (not allowed) and result in the return of an error message.
1Default forward search key 2Default reverse search key If you use the reverse search key option with a set of records that has duplicate keys, only the first record in the set is returned. An application that needs to access all records having duplicate key values requires additional compiler or program logic. On-disk data structures are designed to provide optimum performance for forward searches. Reverse search performance may be diminished, especially for applications that process long chains of deleted records. To take advantage of built-in caching that improves performance when retrieving successive previous records, specify full key sizes and select the next-key option. The following C program demonstrates the use of the search key option. The program reads the last and the next-to-last records in a file.
You can use the Find service (similar to the Get service), in sequential access mode, random access by RFA mode, or random access by key access mode. When finding records in random access by key access mode, your program can specify any one of the four types of key matches (exact, generic, approximate, generic/approximate) described in Section 2.1.1.2 and Section 8.4.3.2. In addition to reading, writing, and finding a record, your program can delete or update any record in an indexed file if the operation does not violate specified key characteristics. For example, if the program specifies that key values cannot be changed, any update that attempts to change a key value is rejected. The next section describes how indexed files are used with the sequential and random access by key modes. 8.4.3.1 Sequential AccessYou can use sequential record access mode to retrieve successive records in an indexed file. RMS retrieves the records in successive order by the specified sort order for a key of reference. The key of reference (for example, primary key, first alternate key, second alternate key, and so forth) is established through one of the following services:
When the sequential access mode is used with the Put service to insert records into an indexed file, successive records must be in the specified sort order by primary key. 8.4.3.2 Random AccessOne of the most useful features of indexed files is that you can randomly retrieve records by the record's key value. A key value and a key of reference (such as a primary key, first alternate key, and so forth) can be specified as input to the record-processing service. RMS searches the specified index to locate the record with the specified key value. When reading records in random access by key mode, your program may specify one of four types of key matches:
Exact match requires that the record's key value precisely match the key value specified by the program's Get service. Approximate key match allows the program to select one of the following options:
The advantage of using an approximate key match is that your program can retrieve a record without knowing its precise key value. RMS uses the approximations in your program to return the record with the key value nearest the specified value. If you elect to use a generic key match, your program need provide only a specified number of leading characters in the key, for example, the first 5 bytes (characters) of a 10-byte string data-type key.
RMS uses this information to return the first record with a key value that begins with these characters and meets the specified sorting order requirement. This is useful when attempting to locate a record when only part of the key is known or for applications in which a series of records must be retrieved when only the initial portions of their key values are identical. Generic key match is available for string keys only. For example, if the program specifies the next-key option with a generic match on the three characters RAM using ascending sort order, RMS returns records with key values RAMA, RAMBO, and RAMP in that order. A record having the same key value RAM is not returned. If you specify the next-key option and descending sort order, RMS returns records with key values RAMP, RAMBO, and RAMA in that order. When a generic key match is used with various approximate key match options, the results can vary, as shown in the following example. Consider using a key value of ABB to access records having key values of ABA, ABB, and ABC, respectively.
Now observe the effects of varying the search key option and the length of the generic string.
Now consider an example of how to return all the records in a file with key values that match the generic string AB.
This procedure can be used to return all records that match a specified duplicate key for a key that allows duplicates. An alternative to checking the characters is to specify an ending key value and set the key-limit option when the record access mode is changed to sequential. When accessing an indexed file randomly by key, the key value must reside in the area of memory identified by the control block offset RAB$L_KBF. When using string keys, you should specify the key length in the location identified by control block offset RAB$B_KSZ. 8.4.4 Access by Record File Address (RFA)Random access by RFA is supported for all disk files. Whenever RMS successfully accesses a record, an internal representation of the record's location is returned in the 6-byte RAB field RAB$W_RFA. When a program wants to retrieve the record using random access by RFA, RMS uses this internal data to retrieve the record. One way to use RFA access is to establish a record position for later sequential accesses. Consider a sequential file with variable-length records that can only be accessed randomly using RFA access. Assume the file consists of a list of transactions, sorted previously by account value. Because each account may have multiple transactions, each account value may have multiple records for it in the file. Instead of reading the entire file until it finds the first record for the desired account number, it uses a previously saved RFA value and random access by RFA to set the current-record position using a Find service at the first record of the desired account number. It can then switch to sequential record access and read all successive records for that account, until the account number changes or the end of the file is reached. Figure 8-1 shows how the file is accessed for account C. Figure 8-1 Using RFA Access to Establish Record Position 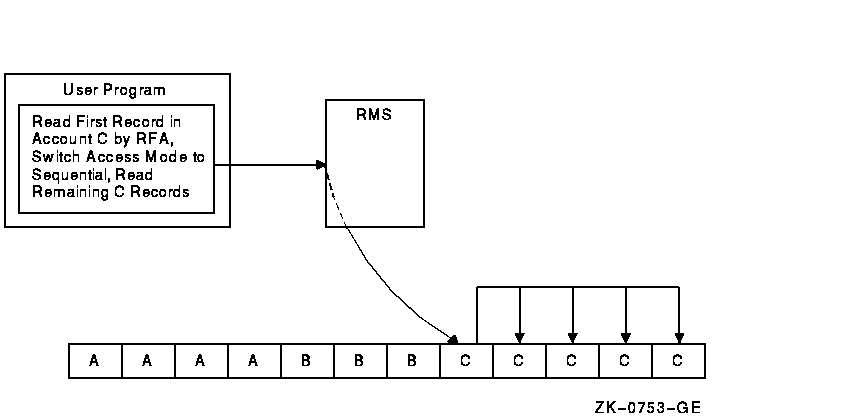
8.5 Block Input/OutputBlock input/output (I/O) lets you bypass the record-processing capabilities entirely. In this manner, your program can process a file as a virtually contiguous set of blocks. Block I/O operations provide an intermediate step between operations and direct use of the Queue I/O Request system service. Using block I/O gives your program full control of the data in the individual blocks of a file while being able to take advantage of the RMS capabilities for opening, closing, and extending a file. In block I/O, a program reads or writes one or more blocks by specifying a starting virtual block number in the file and the length of the transfer. Regardless of the organization of the file, RMS accesses the identified block or blocks. Because RMS files contain internal information meaningful only to RMS itself, Compaq does not recommend that you modify an existing file using block I/O if the file is also to be accessed by record-level operations. (Block I/O does not update any internal record information.) The block I/O facility, however, does allow you to create your own file organizations. This file structure must be maintained through specialized user-written programs and procedures; RMS cannot access these structures with its record access modes. For more information about using block I/O, see the OpenVMS Record Management Services Reference Manual. 8.6 Current Record ContextFor each RAB connected to a FAB, RMS maintains current context information about the record stream including the current-record position and the next-record position. Furthermore, the current context is different for the various services, as shown in Table 8-3. The current record context is internal to RMS; you have no direct contact with it. However, you should know the context for each service in order to properly access records when you invoke a service.
Notes to Table 8-3:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||