OpenVMS �û��ֲ�
9.2 �����ļ�
Ҫ�����ļ���ʹ�� DCL ���� SORT��ָ��Ҫ�����ļ������ö��ŷֿ�����������������������ļ������ơ�
��ѡ�أ�����Ϊ��Ҫ�����ÿ���ֶ�ָ��һ������ÿ��������������Ϣ:
- ��¼�м��ֶεĿ�ʼλ�� (�����)
- ���Ĵ�С (�����)
- ������������
- ��¼����Ĵ���
- �������ȼ�
�����ָ���κμ���Sort �ٶ�ֻ��һ����������������ֶ���:
- �ڼ�¼�ĵ�һ��λ�ÿ�ʼ
- ����������¼
- �����ַ�����
- ����������
������������ʹ��Ĭ�ϼ���
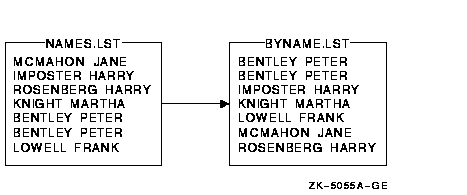
- ����������У��ļ� NAMES.LST ����������:
$ SORT NAMES.LST BYNAME.LST
|
�������������������ļ� BYNAME.LST����ͼ 9-1
��ʾ��
ͼ 9-1 ������������б�
- ����������У��ļ� NAMES.LST �� NAMES2.LST �����������������ļ� BYNAME.LST��Sort �Դ���Щ�ļ�����������һ�����ļ�:
$ SORT NAMES.LST,NAMES2.LST BYNAME.LST
|
�й� SORT ���ʵ������б�������� 9.9 ����
ʹ�� /KEY
���ʶ���һ������ָ�������ʱ��Ϊÿ����ʹ��һ�������� /KEY ���ʡ�
�� 9-2 ������ɼ��� 5 ��Ԫ�ء�
�� 9-2 /KEY ����ֵ
| ��Ԫ�� |
ֵ |
���� |
|
���
|
POSITION:
n
|
���ֶεĵ�һ���ֽ��ڼ�¼�е�λ�á���¼��һ���ֽڵ�λ���� 1��POSITION:
n �DZ���ġ� |
|
����С
|
SIZE:
n
|
���ֶεij��ȡ�SIZE:
n �DZ���ģ��������ݳ��⡣ ָ����Сʱ��Ϊ��ָ������������ȷ��ʲôֵ�ǿɽ��ܵġ��±��г�ÿ�����ݵĿ���ֵ��������ָ������С�ĵ�λ��
| ���� |
��Ч��Χ |
��λ |
|
�ַ�
|
1 �� 32,767
|
�ַ�
|
|
������
|
1��2��4��8 �� 16 (���ڸ����� Sort/Merge ���ó��������������͵ļ���С������ 1��2��4 �� 8 �ֽڡ��� 16
�ֽڶ����Ƽ���֧������������ OpenVMS Alpha ���а汾��)
|
�ֽ�
|
|
ʮ����
|
1 �� 31 |
����
|
|
����
|
����Ҫֵ�� |
����ʮ�������ݣ����ʮ���Ʒ��Ŵ洢��һ�������ֽڣ���ô����ֽڲ��������ݴ�С�ļ����С� ���ָ���ļ�������¼��ĩ�ˣ�Sort
���ȱʧ���ַ��������ַ��� |
|
��������
|
CHARACTER
|
�ַ����ݡ�CHARACTER ��Ĭ���������͡� |
|
|
BINARY
|
���������ݡ�
SIGNED --- �з��ŵĶ����ƻ�ʮ�������ݡ�SIGNED �Ƕ����ƺ�ʮ�������ݵ�Ĭ�ϸ�ʽ�� UNSIGNED ---
���ŵĶ����ƻ�ʮ�������ݡ� |
|
|
F_FLOATING
|
F_FLOATING ��ʽ���ݡ�
|
|
|
D_FLOATING
|
D_FLOATING ��ʽ���ݡ�
|
|
|
G_FLOATING
|
G_FLOATING ��ʽ���ݡ�
|
|
|
H_FLOATING
|
�� VAX ϵͳ�ϣ�H_FLOATING ��ʽ���ݡ�(������ Sort/Merge ���ó���ǰ��֧�֡�)
|
|
|
S_FLOATING
|
�� Alpha ϵͳ�ϣ�IEEE S_FLOATING ��ʽ���ݡ�
|
|
|
T_FLOATING
|
�� Alpha ϵͳ�ϣ�IEEE T_FLOATING ��ʽ���ݡ�
|
|
|
DECIMAL
|
ʮ�������ݡ�
TRAILING_SIGN --- β����ŵ�ʮ�������ݡ�TRAILING_SIGN ��ʮ�������ݵ�Ĭ�ϸ�ʽ��
LEADING_SIGN --- ǰ�����ŵ�ʮ�������ݡ�ǰ�����ű������ֶεĵ�һ��λ�ã�������ֶα������������� OVERPUNCHED_SIGN ---
������ʮ�������ݡ�OVERPUNCHED_SIGN ��ʮ�������ݵ�Ĭ�ϸ�ʽ��
SEPARATE_SIGN --- �������ŵ�ʮ�������ݡ� |
|
|
ZONED
|
������ʮ�������ݡ�(������ Sort/Merge ���ó���ǰ��֧�֡�)
|
|
|
PACKED_DECIMAL
|
ѹ����ʮ�������ݡ�
|
|
�������
|
ASCENDING
|
����������ĸ�����ִ���������������ASCENDING ��Ĭ�ϴ��� |
|
|
DESCENDING
|
���ݼ�����ĸ�����ִ���������������
|
|
�����ȼ�
|
NUMBER:
n
|
���û�а������ǵ����ȼ������г����������ͨ������ָ��ÿ���������ȼ�����ָ��ֵ�� 1 �� 255�� |
������ֶε����ݲ����ַ����ݣ�����ָ�����������͡�Sort/Merge ���ó���ʶ��������������:
|
BINARY��[SIGNED]
|
|
|
BINARY��UNSIGNED
|
|
|
CHARACTER
|
|
|
DECIMAL��LEADING_SIGN��SEPARATE_SIGN [SIGNED]
|
|
|
DECIMAL��LEADING_SIGN��[OVERPUNCHED_SIGN��SIGNED]
|
|
|
DECIMAL [,SIGNED��TRAILING_SIGN��OVERPUNCHED_SIGN]
|
|
|
DECIMAL��[TRAILING SIGN]��SEPARATE_SIGN��[SIGNED]
|
|
|
DECIMAL��UNSIGNED
|
|
|
D_FLOATING
|
|
|
F_FLOATING
|
|
|
G_FLOATING
|
|
|
H_FLOATING
|
|
|
S_FLOATING��IEEE (ֻ���� Alpha ϵͳ)
|
|
|
T_FLOATING��IEEE (ֻ���� Alpha ϵͳ)
|
|
|
PACKED_DECIMAL
|
|
|
ZONED
|
|
���������ڵ���Ŀ��Ĭ�ϵģ�����Ҫָ����
ע��
����ʮ�����ַ������ݣ�Sort/Merge ���ó���Ϊ VAX �� Alpha
ϵͳ���������봮����һ����Ч�����Dz�ͬ�ġ��� VAX
ϵͳ�ϣ�������յ�һ����Ϣ����֪Ϊ�˱Ƚϰ���Ч���� (����������) ת��Ϊ��Ч��ʮ�����ַ������� Alpha ϵͳ�ϣ�Sort/Merge ִ��ͬ����ת����������ʾ������Ϣ������������£����������ļ������ݲ����ĵ�д������ļ��� |
��ͼ 9-2 �У��ļ� EMPLOYEE.LST ��ÿ����¼����
3 ���ֶ�: (1) ��������(2) �ʺź� (3) ��Ա����
ͼ 9-2 �б��еļ�¼�ֶ�

��������˵����ʹ�û�ʹ��һ�����ֶ�ʱ��������� EMPLOYEE.LST �еļ�¼:
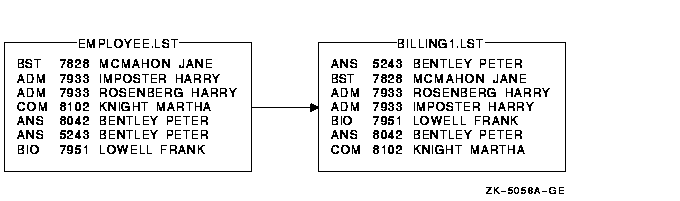
- ����������У�ʹ�� /KEY ���������ʺ��ֶΣ����ʺ����� EMPLOYEE.LST:
$ SORT/KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING1.LST
|
�������ָ�����ֶ� (�ʺ�)
��ʼ��λ�� 5���� 4 ���ַ���������ʮ�������ݣ�����Ӧ�ð��������� (Ĭ��)��ͼ 9-3
չʾ�����������Ľ����
ͼ 9-3 �����ֶ�����
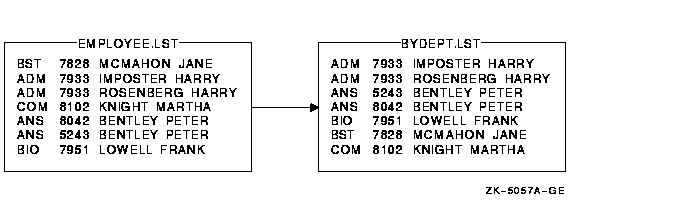
- �������չʾû��ָ�����ֶ�ʱ����������ļ� EMPLOYEE.LST:
$ SORT EMPLOYEE.LST BYDEPT.LST
|
��Ϊû��ָ����������ٶ�Ĭ��������ͼ 9-4
չʾ�����������Ľ����
ͼ 9-4 ��Ĭ�ϼ���¼����
Sort �� EMPLOYEE.LST
��ÿ����¼��Ϊ�ַ����ݵ�һ����������������У�ÿ����¼����һ����������һ���ʺź�һ����Ա�������
Sort
�ҵ��ظ��IJ����������Ͱ��ʺ�����������������ҵ��ظ��ĸ����ʺţ����Ͱ���Ա������ע�⣬�ʺ��Ǽ�¼��һ���֡���������ָ����������Ϊ�ַ����ݡ�
9.2.2 ����ֶ�
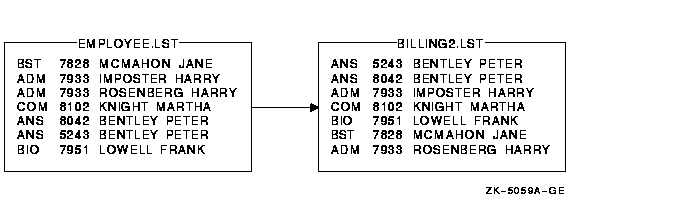
�������ʹ��һ�����ϵļ� (��� 255 �����ļ���)���������ǵ����ȼ�����ָ�����������һ������������һ���Ǹ��������ȵȡ����⣬����ʹ�� NUMBER:n ָ���������ȼ���ÿ�������Ե�����ݼ��� �����������У��ļ� EMPLOYEE.LST
�������Ȱ��չ�Ա������Ȼ�� (����ͬ����¼ʱ) �����ʺż�:
$ SORT /KEY=(POSITION:10,SIZE:15,CHARACTER) -
_$ /KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING2.LST
|
ͼ 9-5 չʾ�����������Ľ����
ͼ 9-5 �ö���ֶ�����
�����������У���¼����ʱ���Ȱ��������Ľ���Ȼ��Ա��������:
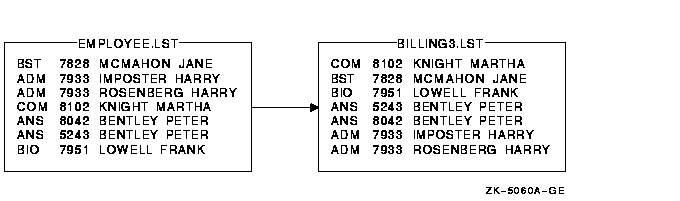
$ SORT/KEY=(POSITION:1,SIZE:3,DESCENDING) -
_$ /KEY=(POSITION:10,SIZE:15) -
_$ EMPLOYEE.LST BILLING3.LST
|
ͼ 9-6 չʾ�����������Ľ����
ͼ 9-6 �ö���ֶ����� (����ͽ���)
9.2.3 ͬ���ļ��ֶ�
����Ĭ�ϣ�Sort/Merge ������ͬ�����ֶεļ�¼�����Dz�ά�������������ļ��г��ֵ�ͬ������Ҫ����ͬ����¼����ķ�������ָ����������֮һ:
- /STABLE
ά��ͬ����¼��������������������ļ�ʱ���ʹ��������ʣ���ô���ͬ����¼ʱ����һ���ļ���ͬ����¼�ڵڶ����ļ���ͬ����¼֮ǰ���Դ����ơ� - /NODUPLICATES
ֻ����ͬ����¼��һ�������������Ҫָ�������ĸ��ظ���¼����ô�ڳ�����
Sort ��ָ��һ���ȼ����г���
/STABLE �� /NODUPLICATES
�����Dz����ݵġ���ͬһ�������в���ͬʱָ�����������ʡ�
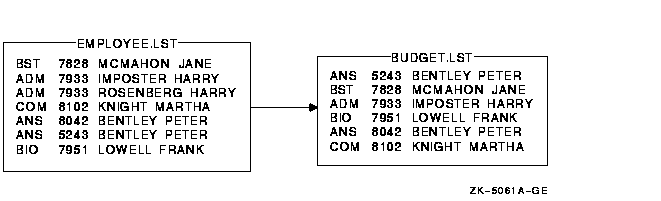
�����������У����ļ� EMPLOYEE.LST �����ظ��ʺŵļ�¼:
$ SORT /KEY=(POSITION:5,SIZE:4)/NODUPLICATES EMPLOYEE.LST BUDGET.LST
|
ͼ 9-7 չʾ�����������Ľ����
ͼ 9-7 ��ͬ���ļ��ֶ�����
9.2.4 ���ַ�����
�������ļ�¼�������ַ����ݵ���Ŀ����ָ��ÿ�������������͡����⣬С�ĵؼ��㿪ʼλ�úʹ�С����Ϊ�Ƚϵ���Ŀ����ռ�� 1 �������ֽڡ�
���Ҫ������ļ���¼���� 20 ���ַ�������� 3
�� F_floating ��ʽ�ĸ���������ô��λ��������ʾ:
- �ַ�����ռ��λ�� 1 �� 20 (20 ���ַ�)��
- ��һ�� F_floating ������ռ��λ�� 21 �� 24��
- �ڶ��� F_floating ������ռ��λ�� 25 �� 28��
- ������ F_floating ������ռ��λ�� 29 �� 32��
Ҫ�������������������ļ���ָ�����ֶ�����:
$ SORT/KEY=(POSITION:29,F_FLOATING) STATS.RAW STATS.SOR
|
����Ҫָ���������Ĵ�С����Ϊ���ǹ̶��ĸ��ֽڡ�
����Ĭ�ϣ��������һ������ļ������ļ���֯���һ�������ļ���ͬ��Ҫָ����ͬ������ļ���֯������ Sort �������У�������ļ�˵��֮�������������֮һ:
- /FORMAT (��¼��ʽ)
��ʹ������������ʱ�����Զ����ļ���¼��ʽ�����ȺͿ��С�� - /INDEXED_SEQUENTIAL
ʹ��������ʣ����Զ�������ļ���������˳���ļ���֯�����ָ������˳����Ϊ����ļ���֯��������������²���:
- ��ִ�� Sort ����֮ǰ������һ����Ϊ����ļ��Ŀ��ļ���Sort ��Ҫһ���Ѿ����ڵ�����ļ��������ǿյġ�
- �� SORT �������У�������ļ���֮����� /OVERLAY ���ʡ�/OVERLAY
����ָ�������ļ�Ҫ�������ļ��������¼���ǡ�
- /RELATIVE
ʹ��������ʣ����Զ�������ļ�������ļ���֯�� - /SEQUENTIAL
ʹ��������ʣ����Զ�������ļ���˳���ļ���֯��
�����������У�������˳���ļ� EMPLOYEE.LST ����֮�����һ��˳���ļ�:
$ SORT/KEY=(POSITION:10,SIZE:15) -
_$ EMPLOYEE.LST BYNAME.LST/SEQUENTIAL
|
9.2.6 �������
Sort �����ļ�ʱʹ�������ڲ�����֮һ: ��¼����ǩ����ַ��������(������ Sort/Merge
���ó���ֻ֧�ּ�¼���̡��Ա�ǩ����ַ���������̵�ʵ������������ OpenVMS Alpha ���а汾��) ָ���Ľ��̿���Ӱ�� Sort ������Ч�ʡ��й��Ż� Sort �� Merge ���������飬�����
9.8 ����
�±�����������̡�ʹ��
/PROCESS=type ���ʿ�ָ��������̡�
| ������� |
���� |
���� |
|
��¼
|
RECORD
|
����ʱ���ּ�¼ԭ�������Ҳ���һ������������¼������ļ�����¼��Ĭ��������̡� |
|
��ǩ
|
TAG
|
ֻ������ֶΣ�Ȼ�����¶�ȡ�����ļ�������һ������������¼������ļ���������һ��������¼����һ���� ������̿ռ���٣���ǩ���������õģ���Ϊ�������ڼ���ͨ��ʹ�ý��ٵĹ����ļ��ռ䡣�ڴ��������£���ǩ����ȼ�¼����������Ϊ����Ҫ�����ʱ�����¶�ȡ�����ļ��� |
|
��ַ
|
ADDRESS
|
ֻ������ֶΣ����Ҳ���һ������ļ�������ļ����Զ����Ƹ�ʽ�洢����¼�ļ���ַ (RFA) �������� ��ַ����ȼ�¼����죬���DZ����дһ������ʹ��¼��ַ�������ļ��ļ�¼������ |
|
���� |
INDEX
|
ֻ������ֶΣ����Ҳ���һ���������� RFA ������ļ�
(�Զ����Ƹ�ʽ)�� ���ַ����һ������������ȼ�¼����죬���DZ����дһ������ʹ��¼��ַ�������ļ��ļ�¼������
|
9.3 ָ���Ƚ�˳��
�ַ������Ƚ�˳�������ڰ����ַ����ݵ��ļ�������ʹ��
/COLLATING_SEQUENCE=sequence ������ָ���Ƚ�˳���±������Ƚ�˳����ѡ��:
| �Ƚ�˳�� |
˳�� |
���� |
|
ASCII
|
ASCII
|
�ַ����ݵ�Ĭ�ϱȽ�˳��ASCII ˳���������� (0 �� 9)��Ȼ���Ǵ�д��ĸ (A �� Z)�������Сд��ĸ (a �� z)�� |
|
EBCDIC
|
EBCDIC
|
����һ���� EBCDIC ˳�����������ļ���������Ȼ�� ASCII ��ʾ��EBCDIC
˳������Сд��ĸ (a �� z)��Ȼ���д��ĸ (A �� Z)����������� (0 �� 9)��
|
|
DEC ����ַ���
|
MULTINATIONAL
|
����Ƚ�˳����� DEC ����ַ����Ƚ��ַ� (�������¼ A)����MULTINATIONAL
�ַ�˳���У��ַ��������¹�������:
- ���ж�����ʽ���ַ���������ַ��ıȽ�ֵ (�磬A'��A" �� A` �Ƚ�Ϊ A)��
- Сд��ĸ�ַ������ǵĴ�д��ĸ������ͬ�ıȽ�ֵ (�磬a
�Ƚ�Ϊ A���� a" �Ƚ�Ϊ A")��
- ��������ַ����Ƚ�Ϊ��ͬ����ִ�зֽ�Ƚϡ������Ƚ��ַ�������������������������Ե��ַ�����Ȼ�Ƚ���ͬ��ʵ���ϲ�ͬ�ַ������µIJ������ַ�����Ȼ�Ƚ�Ϊ��ͬ����ô�ͱȽ��ַ������ִ��롣�����ձȽϺ�Сд��ĸ�ַ������ڴ�д��ĸ֮ǰ��
|
|
�����ַ��� (NCS)
|
�Ƚ�˳����
|
�����ıȽ�˳����붨���� NCS ���С��й����飬����� OpenVMS
National Character Set Utility Manual�� (������ Sort/Merge ���ó���֧�ֹ����ַ��� (NCS) �Ƚ�˳��
�� NCS �Ƚ�˳���֧������������ OpenVMS Alpha ���а汾��)
|
|
�û��Զ���˳��
|
(˳���ַ���)
|
ָ��һ���û��Զ���ıȽ�˳���û��Զ���Ƚ�˳��ֻ֧��˵���ļ�������֧�������н��档 (������ Sort/Merge
���ó���֧���û��Զ���ıȽ�˳���û��Զ���Ƚ�˳���֧��Ҫ���������� OpenVMS Alpha ���а汾��) |
|
|
|
ָ��һ�����ַ���˫�ַ����ַ���Χ���ַ������ɶ���һ���Ƚ�˳��(˫�ַ����κ��������ַ��ļ��ϣ��Ƚ�ʱ����������һ���ַ������磬"CH" ���Զ���ɱȽ�Ϊ "C"��) ����ַ���Ӧ������Բ�����ڡ� Ҳ����������Ӧ�İ˽��ơ�ʮ���ƻ�ʮ������ֵ��ʾ�ַ�����Ҫʹ�û��������: %O��%D �� %X��
�������Լ��ıȽ�˳��ʱ������ע�����¹���:
- ���ַ��������� ("") �ڡ�
- �ö��� (,) �ֿ�ÿ���ַ����ַ���Χ�����������б�����Բ�����ڡ�
- Ϊ������ Sort �� Merge �������ַ����������ַ������Ƚ�ֵ���κ�û�бȽ�ֵ���ַ��������ԣ�����ָ�� FOLD �� MODIFICATION ��ѡ�
- ��Ҫ��ζ���һ���ַ���
- ��Ҫʹ������ ("")
ָ�����ַ�����Ϊʹ�û������������ %X0��
- Ҫָ�����ţ��ɰ�����������һ������ ("" "") �ڣ�����ʹ��һ�������������
�����ַ�������һ���Ƚ�˳�����У�˫�ַ� LL �Ƚ�Ϊһ���� L �� M ֮��ĵ��ַ��� ("A"-"L","LL","M"-"Z")
|
ע��
��ʹ�ö���Ƚ�˳�������ϲ��ļ�������һ������ʱ��Ҫ����ʹ�á��ڴ����������������е�˳������̱Ƚ������ַ�����Ϊ���˳�����ʵ�ʵ�ͼ���ַ��������DZ�ʾ��Щ�ַ��Ĵ��룬��˳����˳���齫ʧЧ�� |
��������ʾ��ʹ��˵���ļ������û��Զ���ıȽ�˳���й�˵���ļ������飬�����
9.7 ����
-
��
/COLLATING_SEQUENCE=(SEQUENCE=ASCII,IGNORE=("-"," "))
|
��� /COLLATING_SEQUENCE ���ʼ�ָ���� IGNORE ��ѡ����������ֶ��ڷֽ�֮ǰ�Ƚ�Ϊ��ͬ:
252-3412
252 3412
2523412
|
-
��
/COLLATING_SEQUENCE=(SEQUENCE=("A"-"L","LL","M"-"R","RR","S"-"Z"))
|
��� /COLLATING_SEQUENCE ���ʶ�����һ��˳���ڴ�˳���£�˫�ַ� LL �Ƚ�Ϊ�� L �� M ֮���һ�����ַ�����˫�ַ�
RR �Ƚ�Ϊ�� R �� S
֮���һ�����ַ������⣬��Щ˫�ַ�Ҳ��ͨ������ĸ˳����֡�����Ĭ�ϣ�����û��Զ���˳�����κ������ַ�����Сд��ĸ a �� z��
|