 |
OpenVMS �û��ֲ�
9.4 ��������ҵ��ʽ���� Sort
������ҵ�Ƕ����ڵ�ǰ�Ի��ڶ����еij����
DCL ������̡����Ҫ������ļ�����ô���ǰ� Sort �����ύΪһ��������ҵ����Ϊ������ҪһЩʱ�䡣�й�������ҵ��������̵����飬�����
�� 16 ��
���� 13 ������ 14 ����
�����������ָ�� SORT �����������Ļ��д���������Ĭ��Ŀ¼������Ҫ������ļ�������ȷ�����������������Ĭ��Ŀ¼�������������ļ�˵���а������Ŀ¼��
���������ύ DCL ������� SORTJOB.COM Ϊһ��������ҵ���������к�չʾ������̵��ı�:
! SORTJOB.COM
!
$ SET DEFAULT [USER.PER] ! Set default to location of input
$ SORT/KEY=(POSITION:10,SIZE:15) EMPLOYEE.LST BYNAME.LST
$ TYPE BYNAME.LST
$ EXIT
|
9.4.2 ���������¼
��������ҵ�п����������¼�������Ƿ��� SORT ����֮��ÿ��һ����¼�����������¼���Ա�һ�г���
��ͬʹ���ն������¼��ָ�������ļ�����Ϊ
SYS$INPUT��ʹ�� /FORMAT ����ָ�����ֽ�Ϊ��λ�ļ�¼��С���Կ�Ϊ��λ�Ľ����ļ���С����Լ 6 �� 80 ���ַ��е���һ�顣
��������ʾ������������а��������¼:
! SORTJOB.COM
!
$ SET DEFAULT [USER.PER]
$ SORT/KEY=(POSITION:10,SIZE:15) -
SYS$INPUT-
/FORMAT=(RECORD_SIZE:24,FILE_SIZE:10) -
BYNAME.LST
$ DECK
BST 7828 MCMAHON JANE
ADM 7933 ROSENBERG HARRY
COM 8102 KNIGHT MARTHA
ANS 8042 BENTLEY PETER
BIO 7951 LOWELL FRANK
$ EOD
|
9.5 �ϲ��ļ�
MERGE ����Ѷ�� 10 �� (������ Sort/Merge
���ó���֧�ֶ�� 12 ��) ������ļ���ϳ�һ�����������ļ������Ժϲ�����ͬ����ʽ��ͨ��ͬ�����ֶ�����������ļ���
����Ĭ�ϣ�Merge ��������ļ��м�¼��˳����ȷ��������������ġ������Ҫ Merge ������ָ�� /NOCHECK_SEQUENCE ���ʡ����ָ��
/CHECK_SEQUENCE ���ʶ�һ����¼����ߵ� (���磬���û������һ�������ļ�)��Merge
�ͱ������³���:
%SORT-W-BAD_ORDER, merge input is out of order
��
|
ʹ�� MERGE ����ʱ���Դ��� SORT ����ͬ�������ʣ�������������:
- ����Ϊ Merge ����ָ��һ������ (/PROCESS)��
- /CHECK_SEQUENCE ����ֻ���ںϲ�������
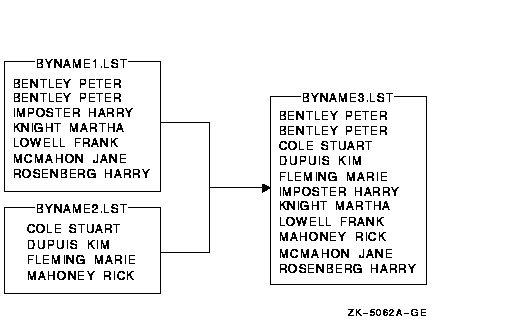
�����������У��ļ� BYNAME1.LST �� BYNAME2.LST
�Ѿ�����Ա����������չʾ��������Ǻϲ�:
$ MERGE BYNAME1.LST,BYNAME2.LST BYNAME3.LST
|
����ļ� BYNAME3.LST ���������������ļ� (����BYNAME1.LST �� BYNAME2.LST) �����м�¼������ͼ��ʾ:
9.5.1 ������ļ�
Ҫ�ϲ�ʹ���ض���������ļ��������� MERGE �������϶� /KEY ����ָ��ͬ���ļ���
�����ָ��һ������Merge ʹ��
9.2 ��������Ĭ�ϼ���
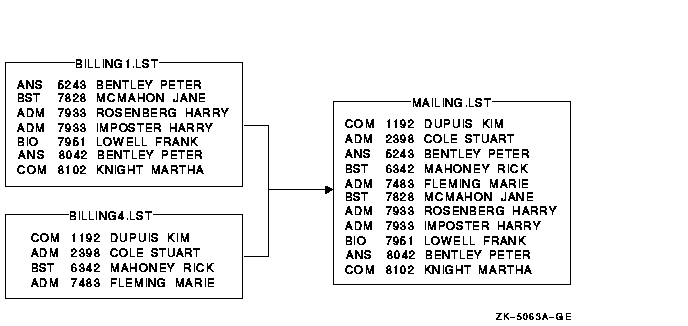
�����������У��ļ� BILLING1.LST �� BILLING4.LST ���ʺ����� (/KEY=POSITION:5,SIZE:4,DECIMAL)��Ҫ����Щ�ļ��ϲ�������ļ� MAILING.LST����������������:
$ MERGE/KEY=(POSITION:5,SIZE:4,DECIMAL) -
_$ BILLING1.LST,BILLING4.LST MAILING.LST
|
�ϲ����������ʾ:
�����Ҫ������Ĵ���ϲ��ļ�����ôָ�� /NOCHECK_SEQUENCE ���ʿ�����ֹ˳���顣
��ͬ Sort �������������ļ�����ͬ�����ֶμ�¼ʱ��Merge
����ά�ּ�¼�������ļ��е�ͬ������Ҫά��ͬ����¼����������� MERGE ��������ָ�� /STABLE
���ʡ�ֻҪ����ͬ����¼��һ��������ָ�� /NODUPLICATES ���ʡ�
��Ҫ�����ϲ��ļ�¼��һ������һ���ļ��������� SORT �� MERGE ����ʱ������ֱ�Ӵ��ն������¼�����±��������������:
| ���� |
���� |
|
1
|
�� SORT �� MERGE �������ϣ�ָ�� SYS$INPUT Ϊ�����ļ��� ʹ�������ļ����� /FORMAT ָ�����ֽ�Ϊ��λ�����¼��С���������ļ��Կ�Ϊ��λ�Ľ��ƴ�С�� |
|
2
|
���������������¼�� ÿ���� Return �ͽ���һ����¼�� |
|
3
|
���� Ctrl/Z �����ļ��� |
��������ʾ��һ�� Sort ������������������¼ֱ�Ӵ��ն�����:
$ SORT/KEY=(POSITION:8,SIZE:15) -
_$ SYS$INPUT/FORMAT=(RECORD_SIZE:24,FILE_SIZE:10) BYNAME.LST
BST 7828 MCMAHON JANE
ADM 7933 ROSENBERG HARRY
COM 8102 KNIGHT MARTHA
ANS 8042 BENTLEY PETER
BIO 7951 LOWELL FRANK
|
���������������¼������ļ� BYNAME.LST��
Sort/Merge ��������˵���ļ���ά�������壬��ָ�������ӵ�������(������ Sort/Merge
���ó���֧��˵���ļ�����������Ե�ʵ������������ OpenVMS Alpha ���а汾��)
����ʹ���κα��༭���� DCL CREATE
�����һ��˵���ļ���
Sort/Merge ˵���ļ�������:
- ѡ�� Sort/Merge ���������ļ�¼
- ���¸�ʽ������ļ��ļ�¼
- ʹ��������������
- ָ�������¼��ʽ
- ��������һ���Ƚ�˳��
-
����ָ�ɹ����ļ�
- �洢Ƶ��ʹ�õ� Sort/Merge ����
�����˵���ļ���ʹ�� /SPECIFICATION ����ָ���ļ�����˵���ļ���Ĭ���ļ������� .SRT�� ˵���ļ���ÿ������Ӧ����һ��б�� (/)
��ʼ�����һ�������Խһ�����ϣ�����Ҫ�����ַ���
ע��
��˵���ļ�ʹ�õ����������������� Sort/Merge ������ʹ�õ� DCL
���ʡ�Ȼ����Ҫע����Щ���ʵ�����Բ�ͬ�����磬�� DCL ����
/KEY ��������˵���ļ��е� /KEY �����в�ͬ������й�˵���ļ����ʵĸ�Ҫ�������
9.9.3 ���� |
����������ָ�����κ� DCL ��������ȡ����˵���ļ��е���Ӧ��Ŀ�����磬����� DCL ��������ָ�� /KEY ���ʣ�Sort/Merge
�ͺ�����˵���ļ��е� /KEY �Ӿ䡣
һ�㣬��˵���ļ���ָ������ʱ���Դ���û�������Ҫ��Ȼ��������������´�������Ҫ��:
- ��һ�����ϼ��ֶ��������û��ָ��
NUMBER:n ��Ԫ��
- ���������ʽ
- ��������¼����
�� /COLLATING_SEQUENCE ����ָ�� FOLD��MODIFICATION �� IGNORE �ؼ���ʱ��Ӧ�����κ� FOLD �Ӿ�֮ǰָ������
MODIFICATION �� IGNORE �Ӿ䡣�й� /COLLATING_SEQUENCE ���ʵ����飬�����
9.9.3 ���� ��˵���ļ��п�����ע�ͣ�ÿ��ע������һ����̾�� (!)
��ʼ���� DCL �����в�ͬ��˵���ļ�����Ҫ���ֺ� (-) ���С�
����
- ����һ��˵���ļ������ӣ�������������������������������:
! ����������������������
! ��˵���ļ�
!
/FIELD=(NAME=SIGN,POS:1,SIZ:1) (1)
/FIELD=(NAME=AMT,POS:2,SIZ:4) (2)
/CONDITION=(NAME=CHECK1, (3)
TEST=(SIGN EQ "-"))
/CONDITION=(NAME=CHECK2, (4)
TEST=(SIGN EQ " "))
/INCLUDE=(CONDITION=CHECK1, (5)
KEY=(AMT,DESCENDING),
DATA=SIGN,
DATA=AMT)
/INCLUDE=(CONDITION=CHECK2, (6)
KEY=(AMT,ASCENDING),
DATA=SIGN,
DATA=AMT)
|
���˵���ļ�ʱ��ע�����¼���:
- ��������ж���һ����ʼ�ڼ�¼�ĵ� 1 �ֽڲ����� 1 �ֽڳ����ֶΡ���Ϊ����ֶ�ָ������ SIGN��
-
��������ж���һ����ʼ�ڼ�¼�ĵ� 2 �ֽڲ����� 4 �ֽڳ����ֶΡ���Ϊ����ֶ�ָ������ AMT��
- ����һ��������䡣����� SIGN �ֽ�����һ������ ( - )������ CHECK1 ������
- ����
һ��������䡣��� SIGN �ֽ��ǿհף����� CHECK2 ������
- ����������� CHECK1����¼����������
- ����������� CHECK2�����¼����������
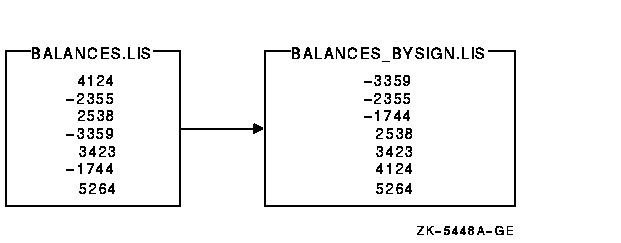
ͼ 9-8 չʾ�������ļ� BALANCES.LIS
��ʹ��˵���ļ��Ľ����
ͼ 9-8 ʹ��˵���ļ������
-
��
/FIELD=(NAME=RECORD_TYPE,POS:1,SIZ:1) ! ��¼���ͣ�1 �ֽ�
/FIELD=(NAME=PRICE,POS:2,SIZ:8) ! �۸������ļ�
/FIELD=(NAME=TAXES,POS:10,SIZ:5) ! ˰�������ļ�
/FIELD=(NAME=STYLE_A,POS:15,SIZ:10) ! ��ʽ����ʽ�� A �ļ�
/FIELD=(NAME=STYLE_B,POS:20,SIZ:10) ! ��ʽ����ʽ�� B �ļ�
/FIELD=(NAME=ZIP_A,POS:25,SIZ:5) ! �������룬��ʽ�� A �ļ�
/FIELD=(NAME=ZIP_B,POS:15,SIZ:5) ! �������룬��ʽ�� B �ļ�
/CONDITION=(NAME=FORMAT_A, ! �������ԣ���ʽ�� A
TEST=(RECORD_TYPE EQ "A"))
/CONDITION=(NAME=FORMAT_B, ! �������ԣ���ʽ�� B
TEST=(RECORD_TYPE EQ "B"))
/INCLUDE=(CONDITION=FORMAT_A, ! �����ʽ������ A
KEY=ZIP_A,
DATA=PRICE,
DATA=TAXES,
DATA=STYLE_A,
DATA=ZIP_A)
/INCLUDE=(CONDITION=FORMAT_B, ! �����ʽ������ B
KEY=ZIP_B,
DATA=PRICE,
DATA=TAXES,
DATA=STYLE_B,
DATA=ZIP_B)
|
����������У�����˵���ļ�ָ����ָ���������һ���ز������������ֹ�˾�����������ļ����ڵ�һ���ļ��е�һ��λ�ÿ�ʼ�� A �ļ�¼�������ʽ:
|A|PRICE|TAXES|STYLE|ZIP|
1 2 10 15 25
|
�ڵڶ����ļ��е�һ��λ�ÿ�ʼ�� B �ļ�¼��λ�õ�ת����ʽ�����������ֶΣ�������ʾ:
|B|PRICE|TAXES|ZIP|STYLE|
1 2 10 15 20
|
Ҫ����¼ A �ĸ�ʽ�����������ֶ������������ļ��������� /FIELD ���ʶ�����������¼���ֶΡ�Ȼ���� /CONDITION ����ָ��һ�����������������¼�����/INCLUDE
���������ʱ������ B �ļ�¼��ʽ����Ϊ����
A �ļ�¼��ʽ��
ע�⣬����� /INCLUDE
������ָ�����������ֶΣ������� /INCLUDE ������Ϊ Sort ������ȷ��ָ�����м��������ֶΡ�
ҲҪע�⣬����ʱ��ʡ�Բ������� A Ҳ�������� B �ļ�¼�� -
��
/COLLATING_SEQUENCE=(SEQUENCE=
("AN","EB","AR","PR","AY","UN","UL",
"UG","EP","CT","OV","EC","0"-"9"),
MODIFICATION=("'"="19"),
FOLD)
|
��� /COLLATING_SEQUENCE
����ָ��һ���û��Զ���˳�����˳��Ϊÿ���¸���һ��Ψһֵ�����磬�����Ҫ�������������ļ� SEMINAR.DAT����ô�ļ� SEMINAR.DAT ������������:
16 NOV 1983 Communication Skills
05 APR 1984 Coping with Alcoholism
11 Jan '84 How to Be Assertive
12 OCT 1983 Improving Productivity
15 MAR 1984 Living with Your Teenager
08 FEB 1984 Single Parenting
07 Dec '83 Stress --- Causes and Cures
14 SEP 1983 Time Management
|
���������ֶΣ������������ֶΡ���Ϊ���ֶβ������֣�����Ҫ�����˳�������·ݣ���˱��붨���Լ��ıȽ�˳�������������������˳������ÿ���·ݵĺ�������ĸ����Ϊÿ���·ݸ���Ψһ��ֵ��
MODIFICATION ��ѡ��ָ��ʡ�Ժ� (')
��ͬ�� 19���Ӷ������Ƚ� '83 �� 1984��FOLD
��ѡ��ָ����д��ĸ��Сд��ĸ��Ϊ��ͬ��
��� Sort ���������������ʾ:
14 SEP 1983 Time Management
12 OCT 1983 Improving Productivity
16 NOV 1983 Communication Skills
07 Dec '83 Stress --- Causes and Cures
11 Jan '84 How to Be Assertive
08 FEB 1984 Single Parenting
15 MAR 1984 Living with Your Teenager
05 APR 1984 Coping with Alcoholism
|
�йؽ����û��Զ���Ƚ�˳����������ӣ������ 9.3 ���� -
��
/FIELD=(NAME=AGENT,POSITION:20,SIZE:15)
/CONDITION=(NAME=AGENCY,
TEST=(AGENT EQ "Real-T Trust"
OR
AGENT EQ "Realty Trust"))
/DATA=(IF AGENCY THEN "Realty Trust" ELSE AGENT)
|
����������У������ز��ļ�������һ���ļ���һ������Ϊ Real-T Trust����һ���ļ���ͬһ����Ϊ Realty Trust��/CONDITION �� /DATA ����ָʾ
Sort �������������ļ��е� AGENT �ֶ���Ϊ Realty Trust�� -
��
/FIELD=(NAME=ZIP,POSITION:60,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/KEY=(IF LOCATION THEN 1
ELSE 2)
|
����������У����д��������� 01863 �ļ�¼�����������������ļ��Ŀ�ʼ���������������� /FIELD ���ʶ���� ZIP �ֶΣ�����������Ϊ LOCATION������� /KEY ���ʵ�ֵ 1
�� 2 ��ʾ��Щ����Ͳ�����������¼����Դ��� -
��
/FIELD=(NAME=ZIP,POSITION:60,SIZE:6)
/CONDITION=(NAME=LOCATION,
TEST=(ZIP EQ "01863"))
/DATA=(IF LOCATION THEN "NORTH CHELMSFORD"
ELSE "Outside district")
|
����������У�/CONDITION ���ʲ��� 01863 �������롣/DATA
����ָ�������ֶ����ƽ����ӵ������¼���Ӳ��Խ�������� -
��
/FIELD=(NAME=FFLOAT,POS:1,SIZ:0,F_FLOATING)
/CONDITION=(NAME=CFFLOAT,TEST=(FFLOAT GE 100))
/OMIT=(CONDITION=CFFLOAT)
|
����������У������ 100 ����Ϊ��һ��
F_FLOATING �������ͣ���Ϊ�� /FIELD �������ֶ� FFLOAT ������Ϊ F_FLOATING���� -
��
/FIELD=(NAME=AGENT,POSITION:1,SIZE:5)
/FIELD=(NAME=ZIP,POSITION:6,SIZE:3)
/FIELD=(NAME=STYLE,POSITION:10,SIZE:5)
/FIELD=(NAME=CONDITION,POSITION:16,SIZE:9)
/FIELD=(NAME=PRICE,POSITION:26,SIZE:5)
/FIELD=(NAME=TAXES,POSITION:32,SIZE:5)
/DATA=PRICE
/DATA=" "
/DATA=TAXES
/DATA=" "
/DATA=STYLE
/DATA=" "
/DATA=ZIP
/DATA=" "
/DATA=AGENT
|
/FIELD ���ʶ��������ļ���¼���ֶ������¸�ʽ:
AGENT ZIP STYLE CONDITION PRICE TAXES
|
/DATA ���ʣ�ʹ��
/FIELD ���ʶ���� field-names�����¸�ʽ����¼�������������¸�ʽ�������¼:
PRICE TAXES STYLE ZIP AGENT
|
9.8 �Ż� Sort �� Merge ����
�����������м��ַ���������� Sort �� Merge ������Ч�ʡ��� SORT �� MERGE ������ʹ�� /STATISTICS
���ʿɻ���й������б�������Ϣ��
�ڼ��ͳ����ʾ�������¼���������κ��Ż���ѡ�
������ SORT �� MERGE ����ʹ�� /STATISTICS
����ʱ���ɿ����������µ����:
$ SORT/STATISTICS PAGEANT.LIS DOCUMENT.LIS
OpenVMS Sort/Merge Statistics
Records read: 3 (1) Input record length: 26
Records sorted: 3 Internal length: 28
Records output: 3 Output record length: 26
Working set extent: 16384 (2) Sort tree size: 42
Virtual memory: 392 Number of initial runs: 0
Direct I/O: 10 Maximum merge order: 0
Buffered I/O: 11 Number of merge passes: 0
Page faults: 158 (3) Work file allocation: 0 (4)
Elapsed time: 00:00:00.54 Elapsed CPU: 00:00:00.03 (5)
|
�������Щ�ֶ�ʱ��ע�����¼���:
- ��ȡ��¼
�г��� Sort �����ڼ��ȡ�ļ�¼�����й�ѡ���Եش� Sort ����ʡ�Լ�¼�����飬�����
9.8.2 ����
- ��������Χ
չʾ�������ٿ�洢��ִ������������й��������������飬�����
9.8.4 ���� - ҳ����
չʾ����ϵͳ���ٴΰѲ��ֽ��̴������ڴ洫�䵽��ҳ�豸���й���ֹ��ҳ�����飬�����
9.8.4 ���� -
�����ļ�����
չʾΪ�����ļ��������ٴ��̿ռ䡣�йع����ļ������飬�����
9.8.3 ���� - CPU ʹ��ʱ��
չʾ����ϵͳʹ�ö��� CPU ʱ�䴦������������й�ͨ����ѡ��ͬ������ʡʱ������飬�����
9.8.1 ����
9.8.1 �������
�ڲ���������ʱ Sort ���������ĸ�����: ��¼����ǩ����ַ��������(������ Sort/Merge
���ó���ֻ֧�ּ�¼���̡��Ա�ǩ����ַ���������̵�ʵ������������ OpenVMS Alpha ���а汾��) RECORD ��Ĭ�Ͻ��̡���ѡ���̵�����Ӱ��
Sort �������ܺʹ洢�����йز�ͬ������̵����飬�����
9.2.6 ���� ��ѡ���������֮ǰ���������¼���:
- ���ʹ������ļ�
- ��Ϊ��¼�ͱ�ǩ��������������������¼���ļ��������Щ����������ļ��������á�
- ��ַ���������������ļ����Ա���һ�ֳ�������������� Pascal��Fortran��MACRO �� C
��д�ij�������
- ��ַ������һ������ָ�������ļ���ÿ��ָ��ָ�������ļ��ļ�¼���������������ļ�ʱ������б����������Ƶ� RFA ��һ���ļ��š�����ʹ��ָ���ȡ��¼��
- ���������ļ�ʱ������������һ������ RFA�����ֶκ�һ���ļ��ŵ�����ļ�����Щ���ֶεĸ�ʽ�������ļ�һ�����������������ʱ��Ҫ���ֶε����ݣ���ôѡ������������ʹ�õ�ַ����
�����Բ�ͬ��;��Ҫ�ü��ַ�����һ���ļ����������ļ���¼����ô�洢���Ե�ַ����������ļ�������ļ�������Ҫ���������ʹ������ļ���ȡ���ļ��ļ�¼�� -
�������������ʱ�洢�ռ�
��ǩ����ȼ�¼����ʹ�ý��ٵ���ʱ�洢�ռ䡣��Ϊ
��¼����������ʱ���ּ�¼ԭ������˵��ļ��Ƚϴ�ʱ����ʹ�úܶ���ռ䡣��ַ����������ʹ�ú��ٵ���ʱ�洢�ռ䡣
- ʹ�õ����������豸����
��¼�������ֻ���Խ��ܶ��������Ŵ��ʹ��̵����롣��ǩ�ͼ�¼������������д���κ�����豸����ַ������������������д���ܹ����ܶ��������ݵ��豸��
- �ٶȲ��
����ڲ����мƻ���������ļ�¼����ô��¼����ͨ�������Ľ��̡�����ַ���������������Ľ��̡�
|