Software > OpenVMS Systems > Documentation > 732final > 6318 HP OpenVMS Systems Documentation |
Guidelines for OpenVMS Cluster Configurations
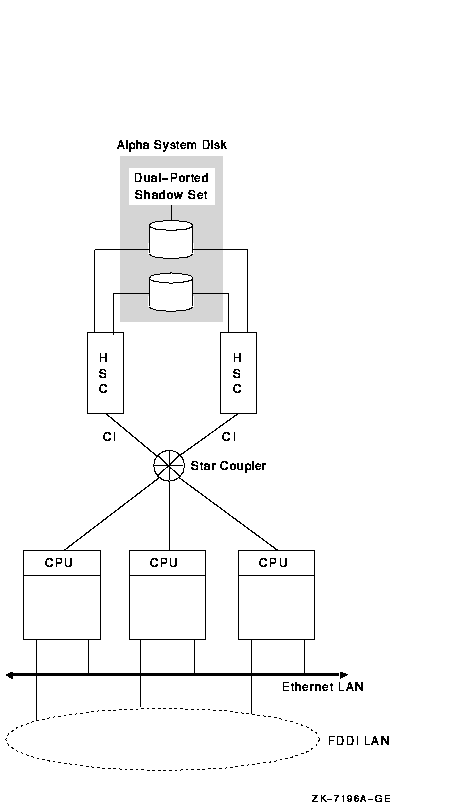
10.7.8 System Parameters for OpenVMS ClustersIn an OpenVMS Cluster with satellites and servers, specific system parameters can help you manage your OpenVMS Cluster more efficiently. Table 10-4 gives suggested values for these system parameters.
1Correlate with bridge timers and LAN utilization. Reference: For a more in-depth description of these parameters, see OpenVMS Cluster Systems and HP Volume Shadowing for OpenVMS. 10.8 Scaling for I/OsThe ability to scale I/Os is an important factor in the growth of your OpenVMS Cluster. Adding more components to your OpenVMS Cluster requires high I/O throughput so that additional components do not create bottlenecks and decrease the performance of the entire OpenVMS Cluster. Many factors can affect I/O throughput:
These factors can affect I/O scalability either singly or in combination. The following sections explain these factors and suggest ways to maximize I/O throughput and scalability without having to change in your application. Additional factors that affect I/O throughput are types of interconnects and types of storage subsystems. Reference: For more information about interconnects, see Chapter 4. For more information about types of storage subsystems, see Chapter 5. For more information about MSCP_BUFFER and MSCP_CREDITS, see OpenVMS Cluster Systems.) 10.8.1 MSCP Served Access to StorageMSCP server capability provides a major benefit to OpenVMS Clusters: it enables communication between nodes and storage that are not directly connected to each other. However, MSCP served I/O does incur overhead. Figure 10-23 is a simplification of how packets require extra handling by the serving system. Figure 10-23 Comparison of Direct and MSCP Served Access 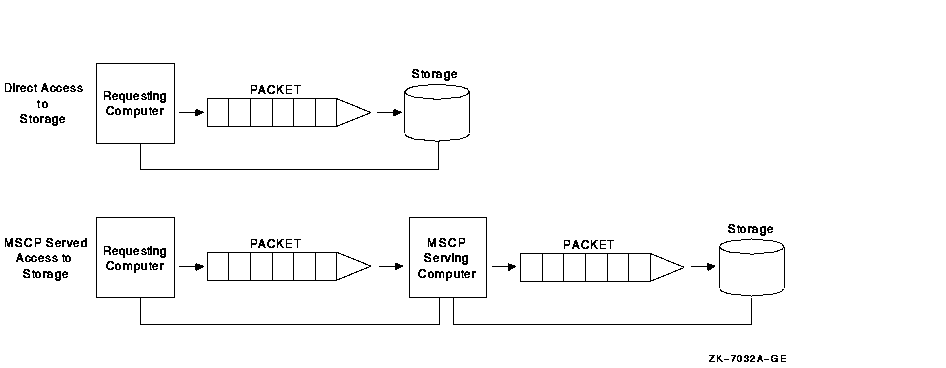
In Figure 10-23, an MSCP served packet requires an extra "stop" at another system before reaching its destination. When the MSCP served packet reaches the system associated with the target storage, the packet is handled as if for direct access. In an OpenVMS Cluster that requires a large amount of MSCP serving, I/O performance is not as efficient and scalability is decreased. The total I/O throughput is approximately 20% less when I/O is MSCP served than when it has direct access. Design your configuration so that a few large nodes are serving many satellites rather than satellites serving their local storage to the entire OpenVMS Cluster. 10.8.2 Disk TechnologiesIn recent years, the ability of CPUs to process information has far outstripped the ability of I/O subsystems to feed processors with data. The result is an increasing percentage of processor time spent waiting for I/O operations to complete. Solid-state disks (SSDs), DECram, and RAID level 0 bridge this gap between processing speed and magnetic-disk access speed. Performance of magnetic disks is limited by seek and rotational latencies, while SSDs and DECram use memory, which provides nearly instant access. RAID level 0 is the technique of spreading (or "striping") a single file across several disk volumes. The objective is to reduce or eliminate a bottleneck at a single disk by partitioning heavily accessed files into stripe sets and storing them on multiple devices. This technique increases parallelism across many disks for a single I/O. Table 10-5 summarizes disk technologies and their features.
Note: Shared, direct access to a solid-state disk or to DECram is the fastest alternative for scaling I/Os. 10.8.3 Read/Write RatioThe read/write ratio of your applications is a key factor in scaling I/O to shadow sets. MSCP writes to a shadow set are duplicated on the interconnect. Therefore, an application that has 100% (100/0) read activity may benefit from volume shadowing because shadowing causes multiple paths to be used for the I/O activity. An application with a 50/50 ratio will cause more interconnect utilization because write activity requires that an I/O be sent to each shadow member. Delays may be caused by the time required to complete the slowest I/O. To determine I/O read/write ratios, use the DCL command MONITOR IO. 10.8.4 I/O SizeEach I/O packet incurs processor and memory overhead, so grouping I/Os together in one packet decreases overhead for all I/O activity. You can achieve higher throughput if your application is designed to use bigger packets. Smaller packets incur greater overhead. 10.8.5 CachesCaching is the technique of storing recently or frequently used data in an area where it can be accessed more easily---in memory, in a controller, or in a disk. Caching complements solid-state disks, DECram, and RAID. Applications automatically benefit from the advantages of caching without any special coding. Caching reduces current and potential I/O bottlenecks within OpenVMS Cluster systems by reducing the number of I/Os between components. Table 10-6 describes the three types of caching.
Host-based disk caching provides different benefits from controller-based and disk-based caching. In host-based disk caching, the cache itself is not shareable among nodes. Controller-based and disk-based caching are shareable because they are located in the controller or disk, either of which is shareable. 10.8.6 Managing "Hot" FilesA "hot" file is a file in your system on which the most activity occurs. Hot files exist because, in many environments, approximately 80% of all I/O goes to 20% of data. This means that, of equal regions on a disk drive, 80% of the data being transferred goes to one place on a disk, as shown in Figure 10-24. Figure 10-24 Hot-File Distribution 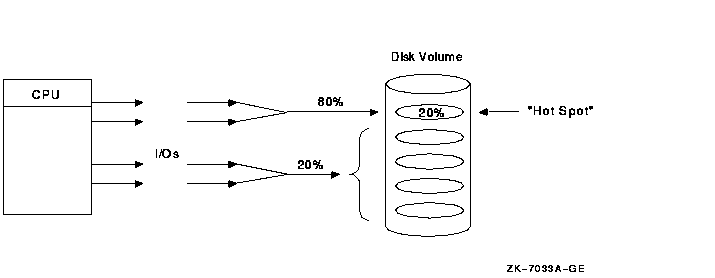
To increase the scalability of I/Os, focus on hot files, which can become a bottleneck if you do not manage them well. The activity in this area is expressed in I/Os, megabytes transferred, and queue depth. RAID level 0 balances hot-file activity by spreading a single file over multiple disks. This reduces the performance impact of hot files. Use the following DCL commands to analyze hot-file activity:
The MONITOR IO and the MONITOR MSCP commands enable you to find out which disk and which server are hot. 10.8.7 Volume ShadowingThe Volume Shadowing for OpenVMS product ensures that data is available to applications and end users by duplicating data on multiple disks. Although volume shadowing provides data redundancy and high availability, it can affect OpenVMS Cluster I/O on two levels:
Chapter 11
|
| Advantage | Description |
|---|---|
| Decreased boot times |
A single system disk can be a bottleneck when booting three or more
systems simultaneously.
Boot times are highly dependent on:
|
| Increased system and application performance |
If your OpenVMS Cluster has many different applications that are in
constant use, it may be advantageous to have either a local system disk
for every node or a system disk that serves fewer systems. The benefits
are shorter image-activation times and fewer files being served over
the LAN.
Alpha workstations benefit from a local system disk because the powerful Alpha processor does not have to wait as long for system disk access. Reference: See Section 10.7.5 for more information. |
| Reduced LAN utilization |
More system disks reduce LAN utilization because fewer files are served
over the LAN. Isolating LAN segments and their boot servers from
unnecessary traffic outside the segments decreases LAN path contention.
Reference: See Section 11.2.4 for more information. |
| Increased OpenVMS Cluster availability | A single system disk can become a single point of failure. Increasing the number of boot servers and system disks increases availability by reducing the OpenVMS Cluster's dependency on a single resource. |
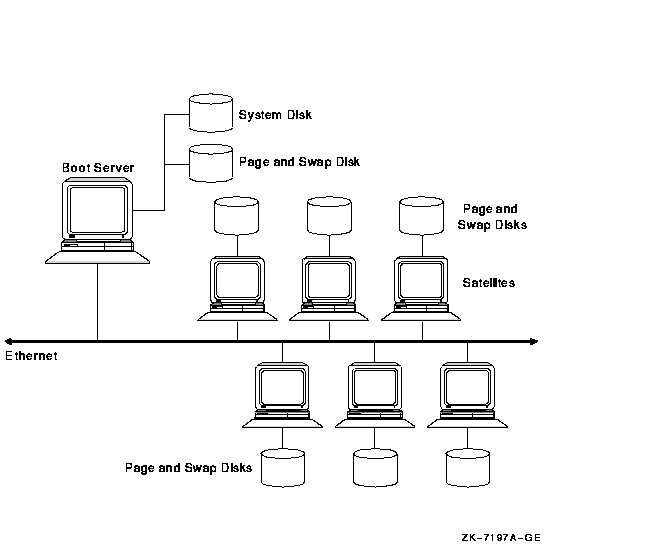
Arranging system disks as shown in Figure 11-3 can reduce booting time and LAN utilization.
Figure 11-3 Multiple System Disks in a Common Environment
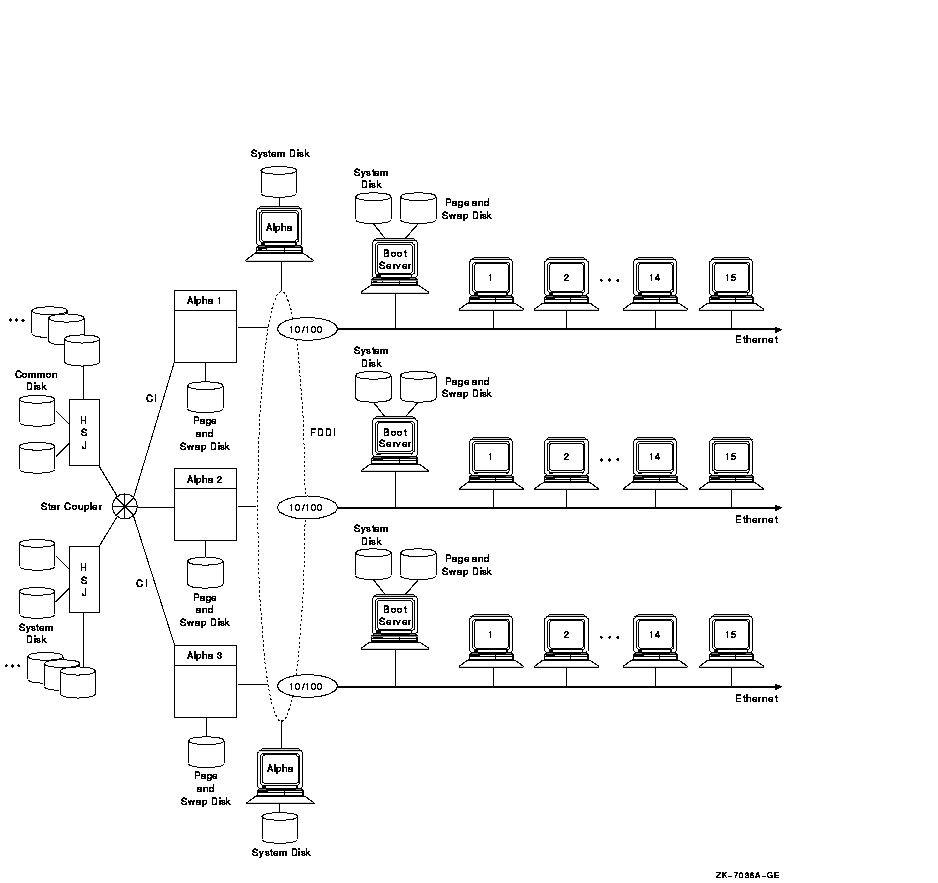
Figure 11-3 is an OpenVMS Cluster with multiple system disks:
The use of multiple system disks in this configuration and the way that the LAN segments are divided enable the booting sequence to be efficient and timely.
In the workstation server examples shown in Section 10.7, OpenVMS Cluster reboots after a failure are relatively simple because of the small number of satellites per server. However, reboots in the larger, OpenVMS Cluster configuration shown in Figure 11-3 require careful planning. Dividing this OpenVMS Cluster and arranging the system disks as described in this section can reduce booting time significantly. Dividing the OpenVMS Cluster can also reduce the satellite utilization of the LAN segment and increase satellite performance.
The disks in this OpenVMS Cluster have specific functions, as described in Table 11-2.
| Disk | Contents | Purpose |
|---|---|---|
| Common disk | All environment files for the entire OpenVMS Cluster |
Environment files such as SYSUAF.DAT, NETPROXY.DAT, QMAN$MASTER.DAT are
accessible to all nodes---including satellites---during booting. This
frees the satellite boot servers to serve only system files and root
information to the satellites.
To create a common environment and increase performance for all system disks, see Section 11.3. |
| System disk | System roots for Alpha 1, Alpha 2, and Alpha 3 | High performance for server systems. Make this disk as read-only as possible by taking environment files that have write activity off the system disk. The disk can be mounted clusterwide in SYLOGICALS.COM during startup. |
| Satellite boot servers' system disks | System files or roots for the satellites | Frees the system disk attached to Alpha 1, Alpha 2, and Alpha 3 from having to serve satellites, and divide total LAN traffic over individual Ethernet segments. |
| Page and swap disks | Page and swap files for one or more systems | Reduce I/O activity on the system disks, and free system disk space for applications and system roots. |
In a booting sequence for the configuration in Figure 11-3, make sure that nodes Alpha 1, Alpha 2, and Alpha 3 are entirely booted before booting the LAN Ethernet segments so that the files on the common disk are available to the satellites. Enable filtering of the Maintenance Operations Protocol (MOP) on the Ethernet-to-FDDI (10/100) bridges so that the satellites do not try to boot from the system disks for Alpha 1, Alpha 2, and Alpha 3. The order in which to boot this OpenVMS Cluster is:
Reference: See Section 10.7.6 for information about extended LANs.
| Previous | Next | Contents | Index |