Software > OpenVMS Systems > Documentation > 82final > 6297 HP OpenVMS Systems Documentation |
HP COBOL
|
| Previous | Contents | Index |
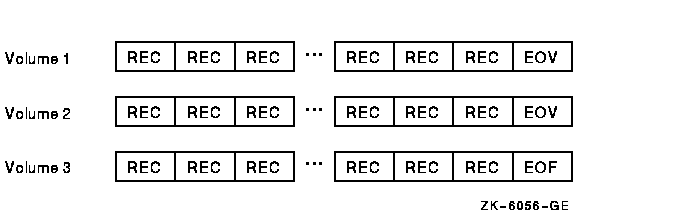
Occasionally a file with sequential organization, for example, a multiple-reel magnetic tape file, is so large that it requires more than one volume. An end-of-volume (EOV) label marks the end of recorded information on each volume and signals the file system to switch to a new volume. On multiple-volume files, the EOF mark appears only once, at the end of the last record on the last volume. Figure 6-2 depicts a multiple-volume, sequential file.
Figure 6-2 A Multiple-Volume, Sequential File
When you select the medium for your sequential file, consider the following:
Refer to the OpenVMS I/O User's Reference Manual or the ltf(4) manpage for more information on magnetic tape formats.
Line Sequential File Organization (Alpha, I64)
Line sequential file structure is essentially similar to the structure of sequential files, with the major difference being record length. Figure 6-3 illustrates line sequential file organization.
Figure 6-3 Line Sequential File Organization (Alpha, I64)
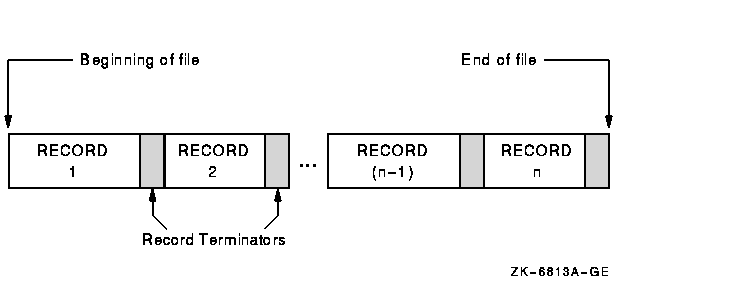
A line sequential file consists of records of varying lengths arranged in the order in which they were written to the file. Each record is terminated with a "newline" character. The newline character is a line feed record terminator ('0A' hex).
Each record in a line sequential file should contain only printable characters and should not be written with a WRITE statements that contains either a BEFORE ADVANCING or AFTER ADVANCING statement.
Record length is determined by the maximum record length in the FD entry in the FILE-CONTROL section and the number of characters in a line (not including the record terminator).
When your HP COBOL program reads a line from a line sequential file that is shorter than the record area, it reads up to the record terminator, discards the record terminator, and pads the rest of the record with a number of spaces necessary to equal the record's specified length. When your program reads a line from a line sequential file that is longer than the record area, it reads the number of characters necessary to fill the record area. The next READ, if any, will begin at the next printable character in the file that is not a record terminator.
Line sequential file organization is useful in reading and printing files that were created by an editor or word processor, which typically do not write fixed-length records. <>
A relative file consists of fixed-size record cells and uses a key to retrieve its records. The key, called a relative key, is an integer that specifies the record's storage cell or record number within the file. It is analogous to the subscript of a table. Relative file processing is available only on disk devices.
Any record on a relative file (unlike a sequential file) can be accessed with one READ operation. Also, relative files allow the program to read forward with respect to the current relative key. In addition to random access by relative key, relative files also permit you to delete and update records by relative key. Relative files are used primarily when records must be accessed in random order and the records can easily be associated with numbers that give the relative positions in the file.
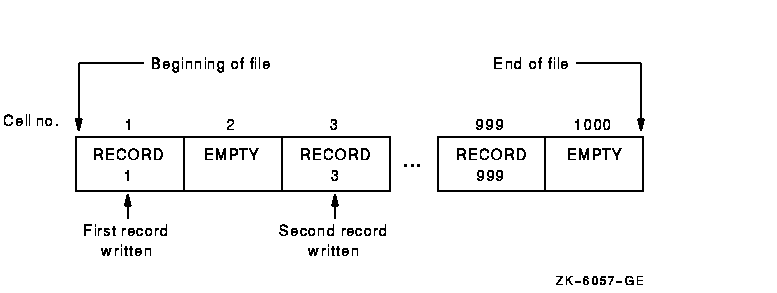
In relative file organization, not every cell must contain a record. Although each cell occupies one record space, a field preceding the record on the storage medium indicates whether or not that cell contains a valid record. Thus, a file can contain fewer records than it has cells, and the empty cells can be anywhere in the file.
The numerical order of the cells remains the same during all operations on a relative file. However, accessing statements can move a record from one cell to another, delete a record from a cell, insert new records into empty cells, or rewrite existing cells.
With relative file processing, the I/O system organizes a file as a series of fixed-sized record cells. Cell size is based on the size specified as the maximum permitted length for a record in the file. The I/O system considers these cells as successively numbered from 1 (the first) to n (the last). A cell's relative record number (RRN) represents its location relative to the beginning of the file.
Because cell numbers in a relative file are unique, they can be used to identify both the cell and the record (if any) occupying that cell. Thus, record number 1 occupies the first cell in the file, record number 21 occupies the twenty-first cell, and so forth. Figure 6-4 illustrates relative file organization.
Figure 6-4 Relative File Organization
Relative files are used like tables. Their advantage over tables is that their size is limited to disk space rather than memory space. Also, their information can be saved from run to run. Relative files are best for records that are easily associated with ascending, consecutive numbers (so that the program conversion from data to cell number is easy), such as months (record keys 1 to 12), or the 50 U.S. states (record keys 1 to 50).
An indexed file uses primary and alternate keys in the record to retrieve the contents of that record. HP COBOL allows sequential, random, and dynamic access to records. You access each record by one of its primary or alternate keys. Indexed file processing is available only on disk devices.
Unlike the sequential ordering of records in a sequential file or the relative positioning of records in a relative file, the physical location of records in indexed file organization is transparent to the program. You can add new records to an indexed file without recreating the file. You can also delete records, making room for new records.
Indexed file organization allows you to use a key to uniquely identify a record within the file. The location and length of the key are identical in all records. When creating an indexed file, you must select the data items to be the keys. Selecting such a data item indicates to the I/O system that the contents (key value) of that data item in any record written to the file can be used by the program to identify that record for subsequent retrieval. For more information, refer to the Environment Division clauses RECORD KEY IS and ALTERNATE RECORD KEY IS in the HP COBOL Reference Manual.
You must define at least one main key, called the primary key, for an indexed file. You may also optionally define from 1 to 254 additional keys called alternate keys. Each alternate key represents an additional data item in each record of the file. You can also use the key value in any of these alternate keys as a means of identifying the record for retrieval.
You define primary and alternate key values in the Record Description entry. Primary and alternate key values need not be unique if you specify the WITH DUPLICATES phrase in the file description entry (FD). When duplicate key values are present, you can retrieve the first record written in the logical sort order of the records with the same key value and any subsequent records using the READ NEXT phrase. The logical sort order controls the order of sequential processing of the record. (For more information about retrieving records with duplicate key values, refer to the information about the READ statement in the HP COBOL Reference Manual.)
When you open a file, you must specify the same number and type of keys that were specified when the file was created. (This situation is subject to modification by the check duplicate keys and relax key checking options, as well as a duplicate key specification on an FD.) If the number or type of keys does not match, the system will issue a run-time diagnostic when you try to open the file.
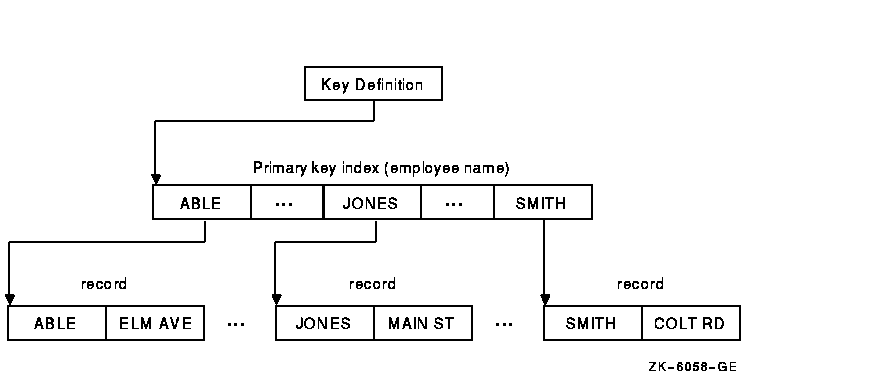
As your program writes records into an indexed file, the I/O system locates the values contained in the primary and alternate keys. The I/O system builds these values into a tree-structured table or index, which consists of a series of entries. Each entry contains a key value copied from a record. With each key value is a pointer to the location in the file of the record from which the value was copied.
Figure 6-5 shows the general structure of an indexed file defined with a primary key only.
Figure 6-5 Indexed File Organization
For a more detailed explanation of indexed file structure on OpenVMS systems, refer to the Guide to OpenVMS File Applications. <>
For information about specifying file organization in your program, see Section 6.2.2.
| Previous | Next | Contents | Index |