Software > OpenVMS Systems > Documentation > 732final > 6318 HP OpenVMS Systems Documentation |
Guidelines for OpenVMS Cluster Configurations
Chapter 8
|
| Availability Requirements | Description |
|---|---|
| Conventional | For business functions that can wait with little or no effect while a system or application is unavailable. |
| 24 x 365 | For business functions that require uninterrupted computing services, either during essential time periods or during most hours of the day throughout the year. Minimal down time is acceptable. |
| Disaster tolerant | For business functions with stringent availability requirements. These businesses need to be immune to disasters like earthquakes, floods, and power failures. |
OpenVMS Cluster systems offer the following features that provide increased availability:
In an OpenVMS Cluster environment, users and applications on multiple systems can transparently share storage devices and files. When you shut down one system, users can continue to access shared files and devices. You can share storage devices in two ways:
OpenVMS Cluster systems allow for redundancy of many components, including:
With redundant components, if one component fails, another is available to users and applications.
OpenVMS Cluster systems provide failover mechanisms that enable recovery from a failure in part of the OpenVMS Cluster. Table 8-2 lists these mechanisms and the levels of recovery that they provide.
| Mechanism | What Happens if a Failure Occurs | Type of Recovery |
|---|---|---|
| DECnet--Plus cluster alias | If a node fails, OpenVMS Cluster software automatically distributes new incoming connections among other participating nodes. |
Manual. Users who were logged in to the failed node can reconnect to a
remaining node.
Automatic for appropriately coded applications. Such applications can reinstate a connection to the cluster alias node name, and the connection is directed to one of the remaining nodes. |
| I/O paths | With redundant paths to storage devices, if one path fails, OpenVMS Cluster software fails over to a working path, if one exists. | Transparent, provided another working path is available. |
| Interconnect | With redundant or mixed interconnects, OpenVMS Cluster software uses the fastest working path to connect to other OpenVMS Cluster members. If an interconnect path fails, OpenVMS Cluster software fails over to a working path, if one exists. | Transparent. |
| Boot and disk servers |
If you configure at least two nodes as boot and disk servers,
satellites can continue to boot and use disks if one of the servers
shuts down or fails.
Failure of a boot server does not affect nodes that have already booted, providing they have an alternate path to access MSCP served disks. |
Automatic. |
| Terminal servers and LAT software |
Attach terminals and printers to terminal servers. If a node fails, the
LAT software automatically connects to one of the remaining nodes. In
addition, if a user process is disconnected from a LAT terminal
session, when the user attempts to reconnect to a LAT session, LAT
software can automatically reconnect the user to the disconnected
session.
|
Manual. Terminal users who were logged in to the failed node must log in to a remaining node and restart the application. |
| Generic batch and print queues |
You can set up generic queues to feed jobs to execution queues (where
processing occurs) on more than one node. If one node fails, the
generic queue can continue to submit jobs to execution queues on
remaining nodes. In addition, batch jobs submitted using the /RESTART
qualifier are automatically restarted on one of the remaining nodes.
|
Transparent for jobs waiting to be dispatched.
Automatic or manual for jobs executing on the failed node. |
| Autostart batch and print queues | For maximum availability, you can set up execution queues as autostart queues with a failover list. When a node fails, an autostart execution queue and its jobs automatically fail over to the next logical node in the failover list and continue processing on another node. Autostart queues are especially useful for print queues directed to printers that are attached to terminal servers. | Transparent. |
Reference: For more information about cluster alias, generic queues, and autostart queues, see OpenVMS Cluster Systems.
Table 8-3 shows a variety of related OpenVMS Cluster software products that HP offers to increase availability.
| Product | Description |
|---|---|
| Availability Manager | Collects and analyzes data from multiple nodes simultaneously and directs all output to a centralized DECwindows display. The analysis detects availability problems and suggests corrective actions. |
| RTR | Provides continuous and fault-tolerant transaction delivery services in a distributed environment with scalability and location transparency. In-flight transactions are guaranteed with the two-phase commit protocol, and databases can be distributed worldwide and partitioned for improved performance. |
| Volume Shadowing for OpenVMS | Makes any disk in an OpenVMS Cluster system a redundant twin of any other same-size disk (same number of physical blocks) in the OpenVMS Cluster. |
The hardware you choose and the way you configure it has a significant impact on the availability of your OpenVMS Cluster system. This section presents strategies for designing an OpenVMS Cluster configuration that promotes availability.
Table 8-4 lists strategies for configuring a highly available OpenVMS Cluster. These strategies are listed in order of importance, and many of them are illustrated in the sample optimal configurations shown in this chapter.
| Strategy | Description |
|---|---|
| Eliminate single points of failure | Make components redundant so that if one component fails, the other is available to take over. |
| Shadow system disks | The system disk is vital for node operation. Use Volume Shadowing for OpenVMS to make system disks redundant. |
| Shadow essential data disks | Use Volume Shadowing for OpenVMS to improve data availability by making data disks redundant. |
| Provide shared, direct access to storage | Where possible, give all nodes shared direct access to storage. This reduces dependency on MSCP server nodes for access to storage. |
| Minimize environmental risks |
Take the following steps to minimize the risk of environmental problems:
|
| Configure at least three nodes |
OpenVMS Cluster nodes require a quorum to continue operating. An
optimal configuration uses a minimum of three nodes so that if one node
becomes unavailable, the two remaining nodes maintain quorum and
continue processing.
Reference: For detailed information on quorum strategies, see Section 11.5 and OpenVMS Cluster Systems. |
| Configure extra capacity | For each component, configure at least one unit more than is necessary to handle capacity. Try to keep component use at 80% of capacity or less. For crucial components, keep resource use sufficiently less than 80% capacity so that if one component fails, the work load can be spread across remaining components without overloading them. |
| Keep a spare component on standby | For each component, keep one or two spares available and ready to use if a component fails. Be sure to test spare components regularly to make sure they work. More than one or two spare components increases complexity as well as the chance that the spare will not operate correctly when needed. |
| Use homogeneous nodes | Configure nodes of similar size and performance to avoid capacity overloads in case of failover. If a large node fails, a smaller node may not be able to handle the transferred work load. The resulting bottleneck may decrease OpenVMS Cluster performance. |
| Use reliable hardware | Consider the probability of a hardware device failing. Check product descriptions for MTBF (mean time between failures). In general, newer technologies are more reliable. |
Achieving high availability is an ongoing process. How you manage your OpenVMS Cluster system is just as important as how you configure it. This section presents strategies for maintaining availability in your OpenVMS Cluster configuration.
After you have set up your initial configuration, follow the strategies listed in Table 8-5 to maintain availability in OpenVMS Cluster system.
| Strategy | Description |
|---|---|
| Plan a failover strategy |
OpenVMS Cluster systems provide software support for failover between
hardware components. Be aware of what failover capabilities are
available and which can be customized for your needs. Determine which
components must recover from failure, and make sure that components are
able to handle the additional work load that may result from a failover.
Reference: Table 8-2 lists OpenVMS Cluster failover mechanisms and the levels of recovery that they provide. |
| Code distributed applications | Code applications to run simultaneously on multiple nodes in an OpenVMS Cluster system. If a node fails, the remaining members of the OpenVMS Cluster system are still available and continue to access the disks, tapes, printers, and other peripheral devices that they need. |
| Minimize change | Assess carefully the need for any hardware or software change before implementing it on a running node. If you must make a change, test it in a noncritical environment before applying it to your production environment. |
| Reduce size and complexity | After you have achieved redundancy, reduce the number of components and the complexity of the configuration. A simple configuration minimizes the potential for user and operator errors as well as hardware and software errors. |
| Set polling timers identically on all nodes |
Certain system parameters control the polling timers used to maintain
an OpenVMS Cluster system. Make sure these system parameter values are
set identically on all OpenVMS Cluster member nodes.
Reference: For information about these system parameters, see OpenVMS Cluster Systems. |
| Manage proactively | The more experience your system managers have, the better. Allow privileges for only those users or operators who need them. Design strict policies for managing and securing the OpenVMS Cluster system. |
| Use AUTOGEN proactively | With regular AUTOGEN feedback, you can analyze resource usage that may affect system parameter settings. |
| Reduce dependencies on a single server or disk | Distributing data across several systems and disks prevents one system or disk from being a single point of failure. |
| Implement a backup strategy | Performing frequent backup procedures on a regular basis guarantees the ability to recover data after failures. None of the strategies listed in this table can take the place of a solid backup strategy. |
Figure 8-1 shows an optimal configuration for a small-capacity, highly available LAN OpenVMS Cluster system. Figure 8-1 is followed by an analysis of the configuration that includes:
Figure 8-1 LAN OpenVMS Cluster System
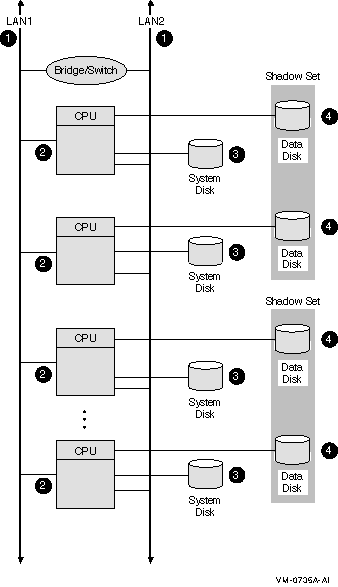
| Component | Description |
|---|---|
| 1 |
Two Ethernet interconnects. For higher network capacity, use FDDI
interconnects instead of Ethernet.
Rationale: For redundancy, use at least two LAN interconnects and attach all nodes to all LAN interconnects. A single interconnect would introduce a single point of failure. |
| 2 |
Three to eight Ethernet-capable OpenVMS nodes.
Each node has its own system disk so that it is not dependent on another node. Rationale: Use at least three nodes to maintain quorum. Use fewer than eight nodes to avoid the complexity of managing eight system disks. Alternative 1: If you require satellite nodes, configure one or two nodes as boot servers. Note, however, that the availability of the satellite nodes is dependent on the availability of the server nodes. Alternative 2: For more than eight nodes, use a LAN OpenVMS Cluster configuration as described in Section 8.10. |
| 3 |
System disks.
System disks generally are not shadowed in LAN OpenVMS Clusters because of boot-order dependencies. Alternative 1: Shadow the system disk across two local controllers. Alternative 2: Shadow the system disk across two nodes. The second node mounts the disk as a nonsystem disk. Reference: See Section 11.2.4 for an explanation of boot-order and satellite dependencies. |
| 4 |
Essential data disks.
Use volume shadowing to create multiple copies of all essential data disks. Place shadow set members on at least two nodes to eliminate a single point of failure. |
This configuration offers the following advantages:
This configuration has the following disadvantages:
The configuration in Figure 8-1 incorporates the following strategies, which are critical to its success:
Follow these guidelines to configure a highly available multiple LAN cluster:
Reference: See Section 10.7.7 for information about extended LANs (ELANs).
When using multiple LAN adapters with multiple LAN segments, distribute the connections to LAN segments that provide MOP service. The distribution allows MOP servers to downline load satellites even when network component failures occur.
It is important to ensure sufficient MOP servers for both VAX and Alpha nodes to provide downline load support for booting satellites. By careful selection of the LAN connection for each MOP server (Alpha or VAX, as appropriate) on the network, you can maintain MOP service in the face of network failures.
| Previous | Next | Contents | Index |