Software > OpenVMS Systems > Documentation > 84final > 4477 HP OpenVMS Systems Documentation |
HP OpenVMS Cluster Systems
Chapter 7
|
| WHEN... | THEN... | Comments |
|---|---|---|
| The node on which the queue manager is running leaves the OpenVMS Cluster system. | The queue manager automatically fails over to another node. | This failover occurs transparently to users on the system. |
| Nodes are added to the cluster. | The queue manager automatically serves the new nodes. | The system manager does not need to enter a command explicitly to start queuing on the new node. |
| The OpenVMS Cluster system reboots. | The queuing system automatically restarts by default. | Thus, you do not have to include commands in your startup command procedure for queuing. |
| The operating system automatically restores the queuing system with the parameters defined in the queuing database. | This is because when you start the queuing system, the characteristics you define are stored in a queue database. |
To control queues, the queue manager maintains a clusterwide queue database that stores information about queues and jobs. Whether you use one or several queue managers, only one queue database is shared across the cluster. Keeping the information for all processes in one database allows jobs submitted from any computer to execute on any queue (provided that the necessary mass storage devices are accessible).
You start up a queue manager using the START/QUEUE/MANAGER command as you would on a standalone computer. However, in an OpenVMS Cluster system, you can also provide a failover list and a unique name for the queue manager. The /NEW_VERSION qualifier creates a new queue database.
The following command example shows how to start a queue manager:
$ START/QUEUE/MANAGER/NEW_VERSION/ON=(GEM,STONE,*) |
The following table explains the components of this sample command.
Running multiple queue managers balances the work load by distributing batch and print jobs across the cluster. For example, you might create separate queue managers for batch and print queues in clusters with CPU or memory shortages. This allows the batch queue manager to run on one node while the print queue manager runs on a different node.
To start additional queue managers, include the /ADD and /NAME_OF_MANAGER qualifiers on the START/QUEUE/MANAGER command. Do not specify the /NEW_VERSION qualifier. For example:
$ START/QUEUE/MANAGER/ADD/NAME_OF_MANAGER=BATCH_MANAGER |
Multiple queue managers share one QMAN$MASTER.DAT master file, but an additional queue file and journal file is created for each queue manager. The additional files are named in the following format, respectively:
By default, the queue database and its files are located in SYS$COMMON:[SYSEXE]. If you want to relocate the queue database files, refer to the instructions in Section 7.6.
When you enter the STOP/QUEUE/MANAGER/CLUSTER command, the queue manager remains stopped, and requests for queuing are denied until you enter the START/QUEUE/MANAGER command (without the /NEW_VERSION qualifier).
The following command shows how to stop a queue manager named PRINT_MANAGER:
$ STOP/QUEUE/MANAGER/CLUSTER/NAME_OF_MANAGER=PRINT_MANAGER |
Rule: You must include the /CLUSTER qualifier on the command line whether or not the queue manager is running on an OpenVMS Cluster system. If you omit the /CLUSTER qualifier, the command stops all queues on the default node without stopping the queue manager. (This has the same effect as entering the STOP/QUEUE/ON_NODE command.)
The files in the queue database can be relocated from the default location of SYS$COMMON:[SYSEXE] to any disk that is mounted clusterwide or that is accessible to the computers participating in the clusterwide queue scheme. For example, you can enhance system performance by locating the database on a shared disk that has a low level of activity.
The master file QMAN$MASTER can be in a location separate from the queue and journal files, but the queue and journal files must be kept together in the same directory. The queue and journal files for one queue manager can be separate from those of other queue managers.
The directory you specify must be available to all nodes in the cluster. If the directory specification is a concealed logical name, it must be defined identically in the SYS$COMMON:SYLOGICALS.COM startup command procedure on every node in the cluster.
Reference: The HP OpenVMS System Manager's Manual contains complete information about creating or relocating the queue database files. See also Section 7.12 for a sample common procedure that sets up an OpenVMS Cluster batch and print system.
To establish print queues, you must determine the type of queue configuration that best suits your OpenVMS Cluster system. You have several alternatives that depend on the number and type of print devices you have on each computer and on how you want print jobs to be processed. For example, you need to decide:
Once you determine the appropriate strategy for your cluster, you can create your queues. Figure 7-1 shows the printer configuration for a cluster consisting of the active computers JUPITR, SATURN, and URANUS.
Figure 7-1 Sample Printer Configuration
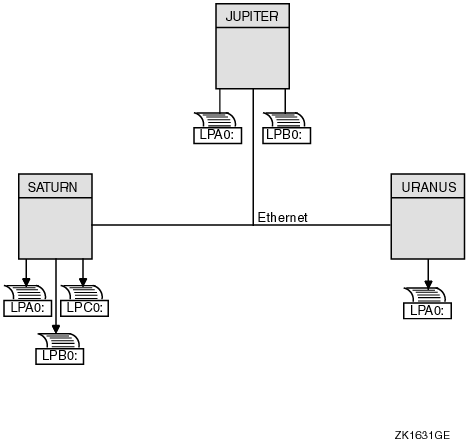
You set up OpenVMS Cluster print queues using the same method that you would use for a standalone computer. However, in an OpenVMS Cluster system, you must provide a unique name for each queue you create.
You create and name a print queue by specifying the INITIALIZE/QUEUE command at the DCL prompt in the following format:
$ INITIALIZE/QUEUE/ON=node-name::device[/START][/NAME_OF_MANAGER=name-of-manager] queue-name |
| Qualifier | Description |
|---|---|
| /ON | Specifies the computer and printer to which the queue is assigned. If you specify the /START qualifier, the queue is started. |
| /NAME_OF_MANAGER | If you are running multiple queue managers, you should also specify the queue manager with the qualifier. |
You can also use the autostart feature to simplify startup and ensure high availability of execution queues in an OpenVMS Cluster. If the node on which the autostart queue is running leaves the OpenVMS Cluster, the queue automatically fails over to the next available node on which autostart is enabled. Autostart is particularly useful on LAT queues. Because LAT printers are usually shared among users of multiple systems or in OpenVMS Cluster systems, many users are affected if a LAT queue is unavailable.
Format for creating autostart queues:
Create an autostart queue with a list of nodes on which the queue can run by specifying the DCL command INITIALIZE/QUEUE in the following format:
INITIALIZE/QUEUE/AUTOSTART_ON=(node-name::device:,node-name::device:, . . . queue-name |
When you use the /AUTOSTART_ON qualifier, you must initially activate the queue for autostart, either by specifying the /START qualifier with the INITIALIZE /QUEUE command or by entering a START/QUEUE command. However, the queue cannot begin processing jobs until the ENABLE AUTOSTART /QUEUES command is entered for a node on which the queue can run. Generic queues cannot be autostart queues.
Rules: Generic queues cannot be autostart queues. Note that you cannot specify both /ON and /AUTOSTART_ON.
Reference: Refer to Section 7.13 for information about setting the time at which autostart is disabled.
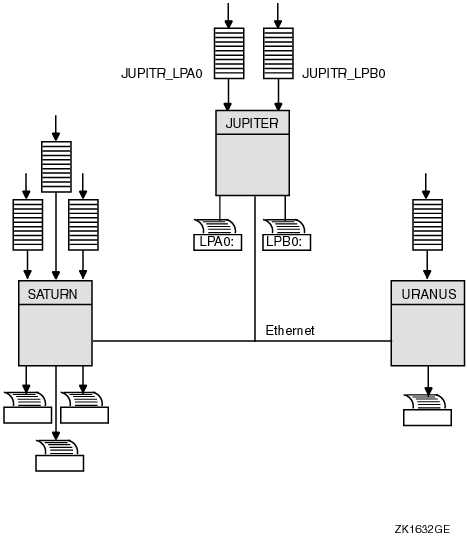
The following commands make the local print queue assignments for JUPITR shown in Figure 7-2 and start the queues:
$ INITIALIZE/QUEUE/ON=JUPITR::LPA0/START/NAME_OF_MANAGER=PRINT_MANAGER JUPITR_LPA0 $ INITIALIZE/QUEUE/ON=JUPITR::LPB0/START/NAME_OF_MANAGER=PRINT_MANAGER JUPITR_LPB0 |
Figure 7-2 Print Queue Configuration
The clusterwide queue database enables you to establish generic queues that function throughout the cluster. Jobs queued to clusterwide generic queues are placed in any assigned print queue that is available, regardless of its location in the cluster. However, the file queued for printing must be accessible to the computer to which the printer is connected.
Figure 7-3 illustrates a clusterwide generic print queue in which the queues for all LPA0 printers in the cluster are assigned to a clusterwide generic queue named SYS$PRINT.
A clusterwide generic print queue needs to be initialized and started only once. The most efficient way to start your queues is to create a common command procedure that is executed by each OpenVMS Cluster computer (see Section 7.12.3).
Figure 7-3 Clusterwide Generic Print Queue Configuration
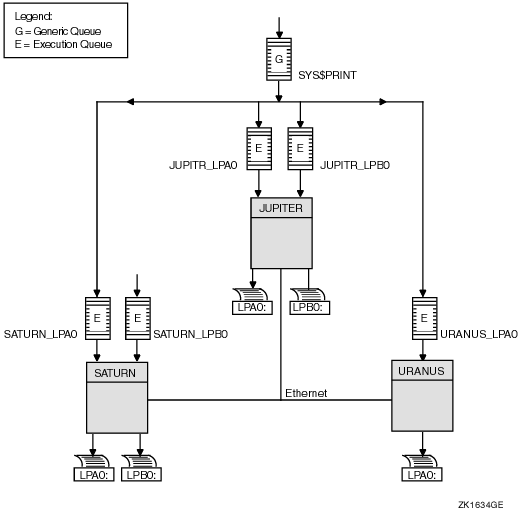
The following command initializes and starts the clusterwide generic queue SYS$PRINT:
$ INITIALIZE/QUEUE/GENERIC=(JUPITR_LPA0,SATURN_LPA0,URANUS_LPA0)/START SYS$PRINT |
Jobs queued to SYS$PRINT are placed in whichever assigned print queue is available. Thus, in this example, a print job from JUPITR that is queued to SYS$PRINT can be queued to JUPITR_LPA0, SATURN_LPA0, or URANUS_LPA0.
Before you establish batch queues, you should decide which type of queue configuration best suits your cluster. As system manager, you are responsible for setting up batch queues to maintain efficient batch job processing on the cluster. For example, you should do the following:
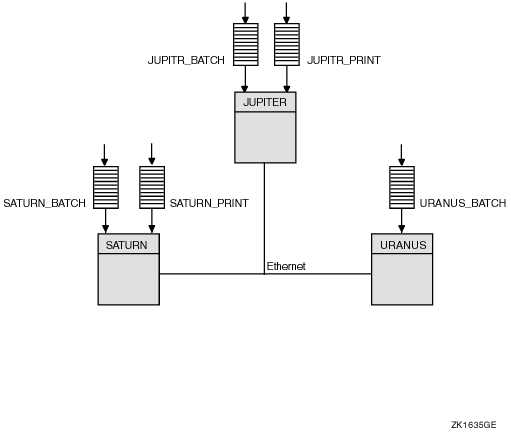
Once you determine the strategy that best suits your needs, you can create a command procedure to set up your queues. Figure 7-4 shows a batch queue configuration for a cluster consisting of computers JUPITR, SATURN, and URANUS.
Figure 7-4 Sample Batch Queue Configuration
You create a batch queue with a unique name by specifying the DCL command INITIALIZE/QUEUE/BATCH in the following format
$ INITIALIZE/QUEUE/BATCH/ON=node::[/START][/NAME_OF_MANAGER=name-of-manager] queue-name |
| Qualifier | Description |
|---|---|
| /ON | Specifies the computer on which the batch queue runs. |
| /START | Starts the queue. |
| /NAME_OF_MANAGER | Specifies the name of the queue manager if you are running multiple queue managers. |
You can initialize and start an autostart batch queue by specifying the DCL command INITIALIZE/QUEUE/BATCH. Use the following command format:
INITIALIZE/QUEUE/BATCH/AUTOSTART_ON=node::queue-name |
When you use the /AUTOSTART_ON qualifier, you must initially activate the queue for autostart, either by specifying the /START qualifier with the INITIALIZE/QUEUE command or by entering a START/QUEUE command. However, the queue cannot begin processing jobs until the ENABLE AUTOSTART /QUEUES command is entered for a node on which the queue can run.
Rule: Generic queues cannot be autostart queues. Note that you cannot specify both /ON and /AUTOSTART_ON.
The following commands make the local batch queue assignments for JUPITR, SATURN, and URANUS shown in Figure 7-4:
$ INITIALIZE/QUEUE/BATCH/ON=JUPITR::/START/NAME_OF_MANAGER=BATCH_QUEUE JUPITR_BATCH $ INITIALIZE/QUEUE/BATCH/ON=SATURN::/START/NAME_OF_MANAGER=BATCH_QUEUE SATURN_BATCH $ INITIALIZE/QUEUE/BATCH/ON=URANUS::/START/NAME_OF_MANAGER=BATCH_QUEUE URANUS_BATCH |
Because batch jobs on each OpenVMS Cluster computer are queued to SYS$BATCH by default, you should consider defining a logical name to establish this queue as a clusterwide generic batch queue that distributes batch job processing throughout the cluster (see Example 7-2). Note, however, that you should do this only if you have a common-environment cluster.
In an OpenVMS Cluster system, you can distribute batch processing among computers to balance the use of processing resources. You can achieve this workload distribution by assigning local batch queues to one or more clusterwide generic batch queues. These generic batch queues control batch processing across the cluster by placing batch jobs in assigned batch queues that are available. You can create a clusterwide generic batch queue as shown in Example 7-2.
A clusterwide generic batch queue needs to be initialized and started only once. The most efficient way to perform these operations is to create a common command procedure that is executed by each OpenVMS Cluster computer (see Example 7-2).
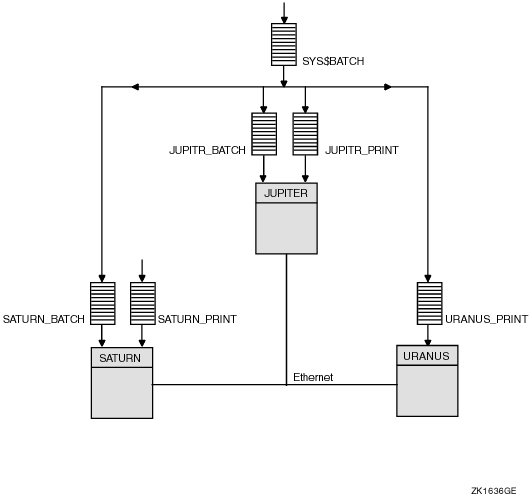
In Figure 7-5, batch queues from each OpenVMS Cluster computer are assigned to a clusterwide generic batch queue named SYS$BATCH. Users can submit a job to a specific queue (for example, JUPITR_BATCH or SATURN_BATCH), or, if they have no special preference, they can submit it by default to the clusterwide generic queue SYS$BATCH. The generic queue in turn places the job in an available assigned queue in the cluster.
If more than one assigned queue is available, the operating system selects the queue that minimizes the ratio (executing jobs/job limit) for all assigned queues.
Figure 7-5 Clusterwide Generic Batch Queue Configuration
Start the local batch execution queue in each node's startup command procedure SYSTARTUP_VMS.COM. If you use a common startup command procedure, add commands similar to the following to your procedure:
$ SUBMIT/PRIORITY=255/NOIDENT/NOLOG/QUEUE=node_BATCH LAYERED_PRODUCT.COM $ START/QUEUE node_BATCH $ DEFINE/SYSTEM/EXECUTIVE SYS$BATCH node_BATCH |
Submitting the startup command procedure LAYERED_PRODUCT.COM as a high-priority batch job before the queue starts ensures that the job is executed immediately, regardless of the job limit on the queue. If the queue is started before the command procedure was submitted, the queue might reach its job limit by scheduling user batch jobs, and the startup job would have to wait.
| Previous | Next | Contents | Index |