Software > OpenVMS Systems > Documentation > 84final > 6318 HP OpenVMS Systems Documentation |
Guidelines for OpenVMS Cluster Configurations
8.8.2 AdvantagesThis configuration offers the following advantages:
8.8.3 DisadvantagesThis configuration has the following disadvantage:
8.8.4 Key Availability StrategiesThe configuration in Figure 8-5 incorporates the following strategies, which are critical to its success:
8.9 Availability in an OpenVMS Cluster with SatellitesSatellites are systems that do not have direct access to a system disk and other OpenVMS Cluster storage. Satellites are usually workstations, but they can be any OpenVMS Cluster node that is served storage by other nodes in the cluster. Because satellite nodes are highly dependent on server nodes for availability, the sample configurations presented earlier in this chapter do not include satellite nodes. However, because satellite/server configurations provide important advantages, you may decide to trade off some availability to include satellite nodes in your configuration. Figure 8-6 shows an optimal configuration for a OpenVMS Cluster system with satellites. Figure 8-6 is followed by an analysis of the configuration that includes:
Figure 8-6 OpenVMS Cluster with Satellites 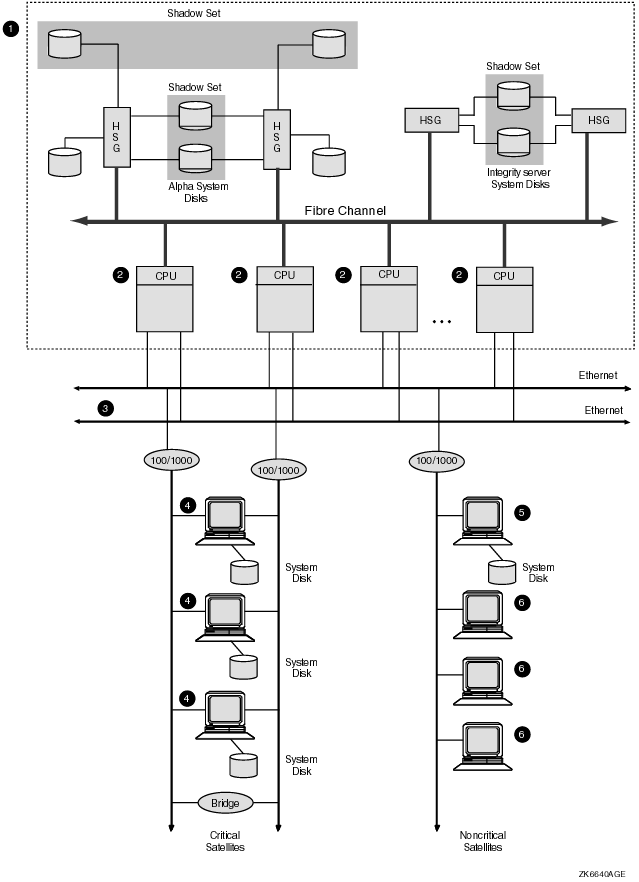
8.9.1 ComponentsThis satellite/server configuration in Figure 8-6 has the following components:
8.9.2 AdvantagesThis configuration provides the following advantages:
8.9.3 DisadvantagesThis configuration has the following disadvantages:
8.9.4 Key Availability StrategiesThe configuration in Figure 8-6 incorporates the following strategies, which are critical to its success:
8.10 Multiple-Site OpenVMS Cluster SystemMultiple-site OpenVMS Cluster configurations contain nodes that are located at geographically separated sites. Depending on the technology used, the distances between sites can be as great as 150 miles. FDDI, and DS3 are used to connect these separated sites to form one large cluster. Available from most common telephone service carriers and DS3 services provide long-distance, point-to-point communications for multiple-site clusters.Figure 8-7 shows a typical configuration for a multiple-site OpenVMS Cluster system. Figure 8-7 is followed by an analysis of the configuration that includes:
Figure 8-7 Multiple-Site OpenVMS Cluster Configuration Connected by WAN Link 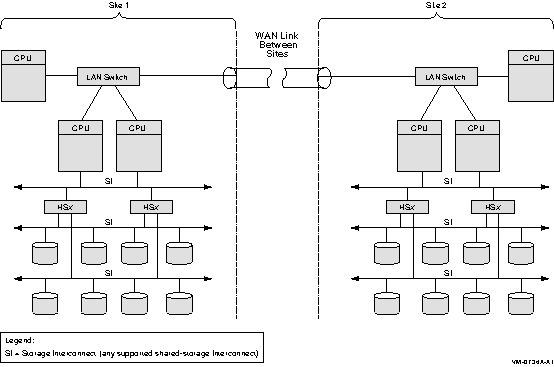
8.10.1 ComponentsAlthough Figure 8-7 does not show all possible configuration combinations, a multiple-site OpenVMS Cluster can include:
8.10.2 AdvantagesThe benefits of a multiple-site OpenVMS Cluster system include the following:
Reference: For additional information about multiple-site clusters, see HP OpenVMS Cluster Systems. 8.11 Disaster-Tolerant OpenVMS Cluster ConfigurationsDisaster-tolerant OpenVMS Cluster configurations make use of Volume Shadowing for OpenVMS, high-speed networks, and specialized management software. Disaster-tolerant OpenVMS Cluster configurations enable systems at two different geographic sites to be combined into a single, manageable OpenVMS Cluster system. Like the multiple-site cluster discussed in the previous section, these physically separate data centers are connected by FDDI or by a combination of FDDI and T3, or E3. The OpenVMS disaster-tolerant product was formerly named the Business Recovery Server (BRS). BRS has been subsumed by a services offering named Disaster Tolerant Cluster Services, which is a system management and software service package. For more information about Disaster Tolerant Cluster Services, contact your HP Services representative.
Chapter 9
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| This Dimension | Grows by... |
|---|---|
| Systems | |
| CPU |
Implementing SMP within a system.
Adding systems to a cluster. Accommodating various processor sizes in a cluster. Adding a bigger system to a cluster. Migrating from Alpha systems to Integrity servers. |
| Memory | Adding memory to a system. |
| I/O |
Adding interconnects and adapters to a system.
Adding MEMORY CHANNEL to a cluster to offload the I/O interconnect. |
| OpenVMS |
Tuning system parameters.
Moving to OpenVMS Integrity servers. |
| Adapter |
Adding storage adapters to a system.
Adding LAN adapters to a system. |
| Storage | |
| Media |
Adding disks to a cluster.
Adding tapes and CD-ROMs to a cluster. |
| Volume shadowing |
Increasing availability by shadowing disks.
Shadowing disks across controllers. Shadowing disks across systems. |
| I/O |
Adding solid-state or DECram disks to a cluster.
Adding disks and controllers with caches to a cluster. Adding RAID disks to a cluster. |
| Controller and array |
Moving disks and tapes from systems to controllers.
Combining disks and tapes in arrays. Adding more controllers and arrays to a cluster. |
| Interconnect | |
| LAN |
Adding Ethernet segments.
Upgrading from Ethernet to Fast Ethernet, Gigabit Ethernet or 10 Gigabit Ethernet. Adding redundant segments and bridging segments. |
| Fibre Channel, SCSI, SAS, and MEMORY CHANNEL | Adding Fibre Channel, SCSI, SAS, and MEMORY CHANNEL interconnects to a cluster or adding redundant interconnects to a cluster. |
| I/O |
Adding faster interconnects for capacity.
Adding redundant interconnects for capacity and availability. |
| Distance |
Expanding a cluster inside a room or a building.
Expanding a cluster across a town or several buildings. Expanding a cluster between two sites (spanning 40 km). |
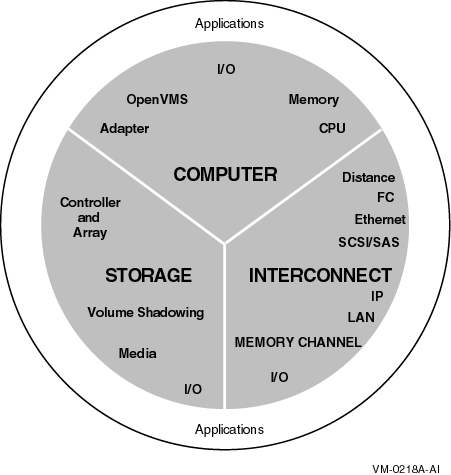
The ability to add to the components listed in Table 9-1 in any way that you choose is an important feature that OpenVMS Clusters provide. You can add hardware and software in a wide variety of combinations by carefully following the suggestions and guidelines offered in this chapter and in the products' documentation. When you choose to expand your OpenVMS Cluster in a specific dimension, be aware of the advantages and tradeoffs with regard to the other dimensions. Table 9-2 describes strategies that promote OpenVMS Cluster scalability. Understanding these scalability strategies can help you maintain a higher level of performance and availability as your OpenVMS Cluster grows.
The hardware that you choose and the way that you configure it has a significant impact on the scalability of your OpenVMS Cluster. This section presents strategies for designing an OpenVMS Cluster configuration that promotes scalability.
Table 9-2 lists strategies in order of importance that ensure scalability. This chapter contains many figures that show how these strategies are implemented.
| Strategy | Description |
|---|---|
| Capacity planning |
Running a system above 80% capacity (near performance saturation)
limits the amount of future growth possible.
Understand whether your business and applications will grow. Try to anticipate future requirements for processor, memory, and I/O. |
| Shared, direct access to all storage |
The ability to scale compute and I/O performance is heavily dependent
on whether all of the systems have shared, direct access to all storage.
The FC and LAN OpenVMS Cluster illustrations that follow show many examples of shared, direct access to storage, with no MSCP overhead. Reference: For more information about MSCP overhead, see Section 9.5.1. |
| Limit node count to between 3 and 16 |
Smaller OpenVMS Clusters are simpler to manage and tune for performance
and require less OpenVMS Cluster communication overhead than do large
OpenVMS Clusters. You can limit node count by upgrading to a more
powerful processor and by taking advantage of OpenVMS SMP capability.
If your server is becoming a compute bottleneck because it is overloaded, consider whether your application can be split across nodes. If so, add a node; if not, add a processor (SMP). |
| Remove system bottlenecks | To maximize the capacity of any OpenVMS Cluster function, consider the hardware and software components required to complete the function. Any component that is a bottleneck may prevent other components from achieving their full potential. Identifying bottlenecks and reducing their effects increases the capacity of an OpenVMS Cluster. |
| Enable the MSCP server | The MSCP server enables you to add satellites to your OpenVMS Cluster so that all nodes can share access to all storage. In addition, the MSCP server provides failover for access to shared storage when an interconnect fails. |
| Reduce interdependencies and simplify configurations | An OpenVMS Cluster system with one system disk is completely dependent on that disk for the OpenVMS Cluster to continue. If the disk, the node serving the disk, or the interconnects between nodes fail, the entire OpenVMS Cluster system may fail. |
| Ensure sufficient serving resources | If a small disk server has to serve a large number disks to many satellites, the capacity of the entire OpenVMS Cluster is limited. Do not overload a server because it will become a bottleneck and will be unable to handle failover recovery effectively. |
| Configure resources and consumers close to each other | Place servers (resources) and satellites (consumers) close to each other. If you need to increase the number of nodes in your OpenVMS Cluster, consider dividing it. See Section 10.2.4 for more information. |
| Set adequate system parameters | If your OpenVMS Cluster is growing rapidly, important system parameters may be out of date. Run AUTOGEN, which automatically calculates significant system parameters and resizes page, swap, and dump files. |
In Figure 9-2, three nodes are connected by two 25-m, fast-wide (FWD) SCSI interconnects. Multiple storage shelves are contained in each HSZ controller, and more storage is contained in the BA356 at the top of the figure.
Figure 9-2 Three-Node Fast-Wide SCSI Cluster
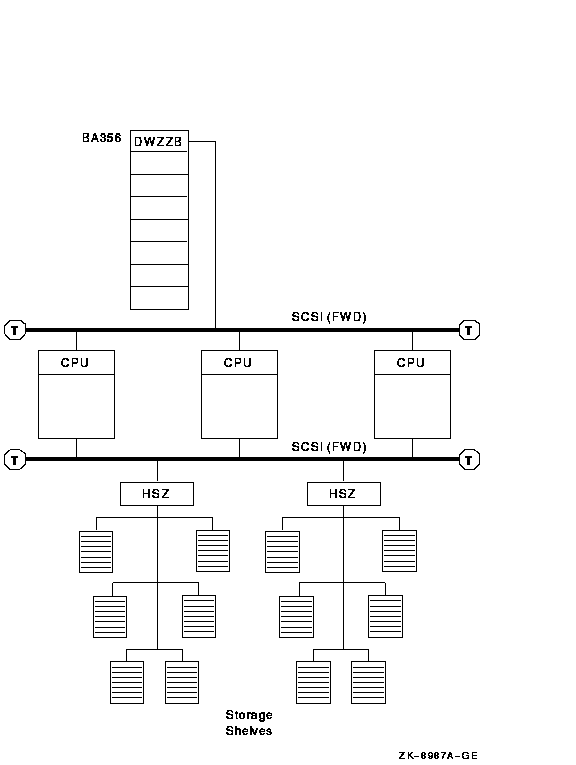
The advantages and disadvantages of the configuration shown in Figure 9-2 include:
Figure 9-3 shows four nodes connected by a SCSI hub. The SCSI hub obtains power and cooling from the storage cabinet, such as the BA356. The SCSI hub does not connect to the SCSI bus of the storage cabinet.
Figure 9-3 Four-Node Ultra SCSI Hub Configuration
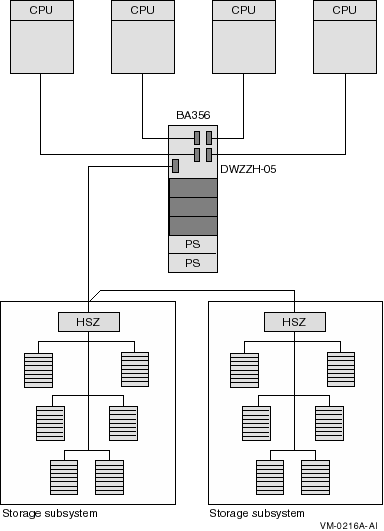
The advantages and disadvantages of the configuration shown in Figure 9-3 include:
The number of satellites in an OpenVMS Cluster and the amount of storage that is MSCP served determine the need for the quantity and capacity of the servers. Satellites are systems that do not have direct access to a system disk and other OpenVMS Cluster storage. Satellites are usually workstations, but they can be any OpenVMS Cluster node that is served storage by other nodes in the OpenVMS Cluster.
Each Ethernet LAN segment should have only 10 to 20 satellite nodes attached. Figure 9-4, Figure 9-5, Figure 9-6, and Figure 9-7 show a progression from a 6-satellite LAN to a 45-satellite LAN.
In Figure 9-4, six satellites and a boot server are connected by Ethernet.
Figure 9-4 Six-Satellite LAN OpenVMS Cluster
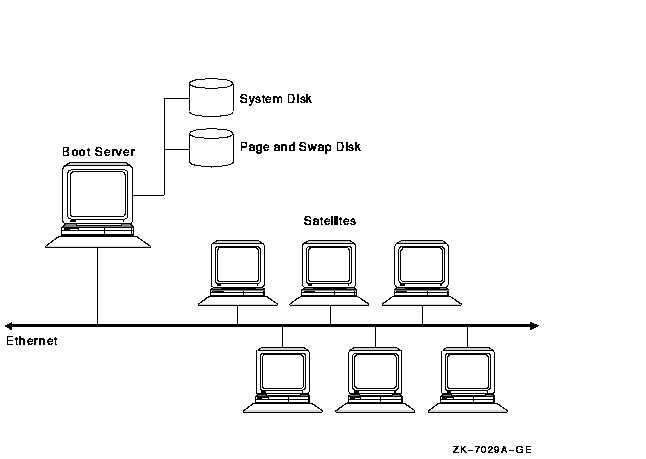
The advantages and disadvantages of the configuration shown in Figure 9-4 include:
If the boot server in Figure 9-4 became a bottleneck, a configuration like the one shown in Figure 9-5 would be required.
| Previous | Next | Contents | Index |