Software > OpenVMS Systems > Documentation > 84final > 6318 HP OpenVMS Systems Documentation |
Guidelines for OpenVMS Cluster Configurations
9.3.2 Six-Satellite OpenVMS Cluster with Two Boot NodesFigure 9-5 shows six satellites and two boot servers connected by Ethernet. Boot server 1 and boot server 2 perform MSCP server dynamic load balancing: they arbitrate and share the work load between them and if one node stops functioning, the other takes over. MSCP dynamic load balancing requires shared access to storage. Figure 9-5 Six-Satellite LAN OpenVMS Cluster with Two Boot Nodes 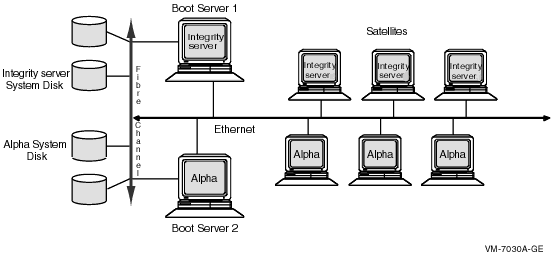
The advantages and disadvantages of the configuration shown in Figure 9-5 include:
If the LAN in Figure 9-5 became an OpenVMS Cluster bottleneck, this could lead to a configuration like the one shown in Figure 9-6. 9.3.3 Twelve-Satellite LAN OpenVMS Cluster with Two LAN SegmentsFigure 9-6 shows 12 satellites and 2 boot servers connected by two Ethernet segments. These two Ethernet segments are also joined by a LAN bridge. Because each satellite has dual paths to storage, this configuration also features MSCP dynamic load balancing. Figure 9-6 Twelve-Satellite OpenVMS Cluster with Two LAN Segments 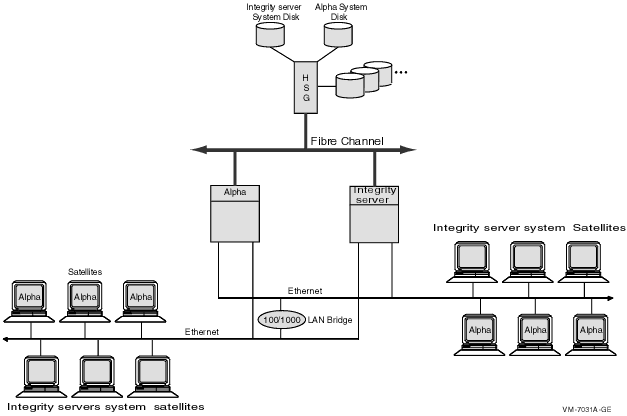
The advantages and disadvantages of the configuration shown in Figure 9-6 include:
If the OpenVMS Cluster in Figure 9-6 needed to grow beyond its current limits, this could lead to a configuration like the one shown in Figure 9-7. 9.3.4 Forty-Five Satellite OpenVMS Cluster with Intersite LinkFigure 9-7 shows a large, 51-node OpenVMS Cluster that includes 45 satellite nodes. The three boot servers, Integrity server 1, Integrity server 2, and Integrity server 3, share three disks: a common disk, a page and swap disk, and a system disk. The intersite link is connected to routers and has three LAN segments attached. Each segment has 15 workstation satellites as well as its own boot node. Figure 9-7 Forty-Five Satellite OpenVMS Cluster with Intersite Link 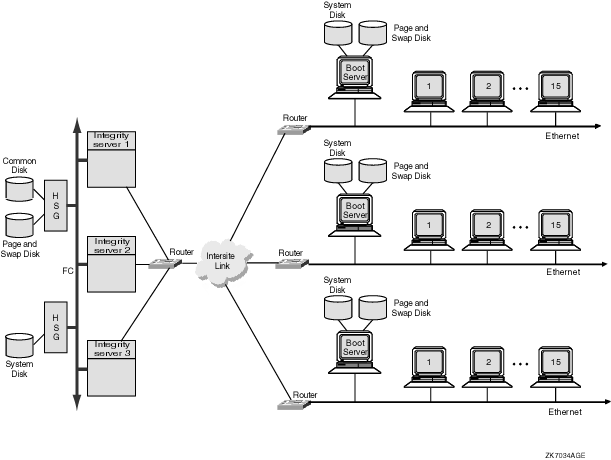
The advantages and disadvantages of the configuration shown in Figure 9-7 include:
9.3.5 High-Powered Workstation OpenVMS Cluster (1995 Technology)Figure 9-8 shows an OpenVMS Cluster configuration that provides high performance and high availability on the FDDI ring.Figure 9-8 High-Powered Workstation Server Configuration 1995 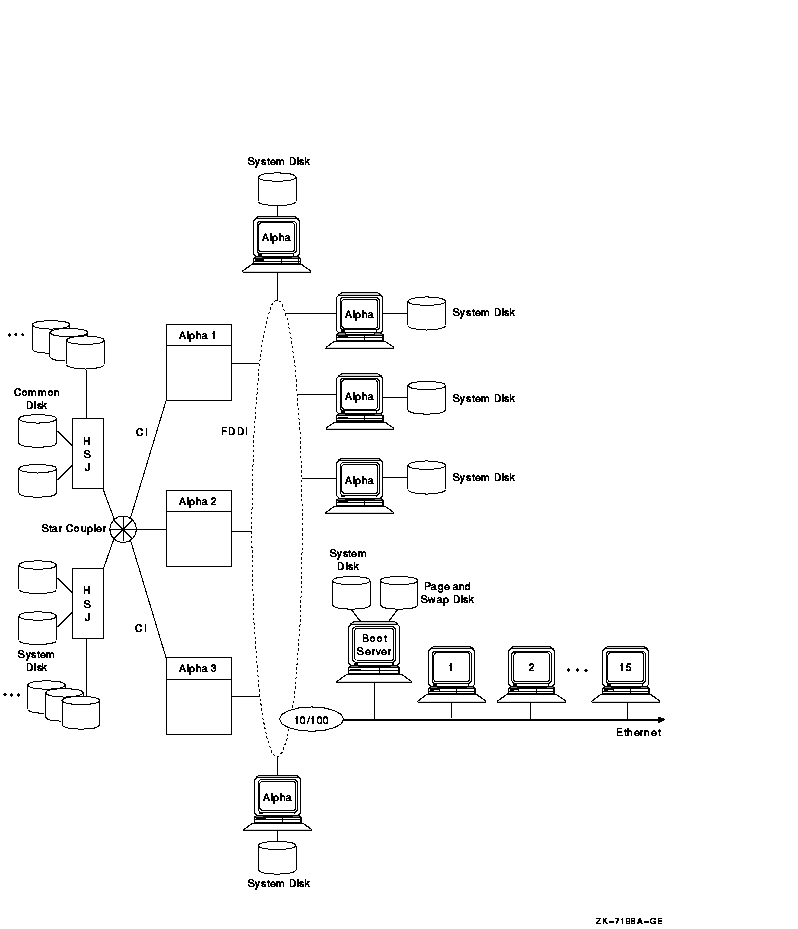
In Figure 9-8, several Alpha workstations, each with its own system disk, are connected to the FDDI ring. Putting Alpha workstations on the FDDI provides high performance because each workstation has direct access to its system disk. In addition, the FDDI bandwidth is higher than that of the Ethernet. Because Alpha workstations have FDDI adapters, putting these workstations on an FDDI is a useful alternative for critical workstation requirements. FDDI is 10 times faster than Ethernet, and Alpha workstations have processing capacity that can take advantage of FDDI's speed. (The speed of Fast Ethernet matches that of FDDI, and Gigabit Ethernet is 10 times faster than Fast Ethernet and FDDI.) 9.3.6 High-Powered Workstation OpenVMS Cluster (2004 Technology)Figure 9-9 shows an OpenVMS Cluster configuration that provides high performance and high availability using Gigabit Ethernet for the LAN and Fibre Channel for storage. Figure 9-9 High-Powered Workstation Server Configuration 2004 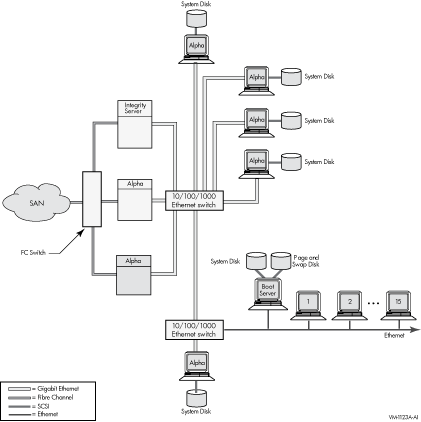
In Figure 9-9, several Alpha workstations, each with its own system disk, are connected to the Gigabit Ethernet LAN. Putting Alpha workstations on the Gigabit Ethernet LAN provides high performance because each workstation has direct access to its system disk. In addition, the Gigabit Ethernet bandwidth is 10 times higher than that of the FDDI. Alpha workstations have processing capacity that can take advantage of Gigabit Ethernet's speed. 9.3.7 Guidelines for OpenVMS Clusters with SatellitesThe following are guidelines for setting up an OpenVMS Cluster with satellites:
9.3.8 Extended LAN Configuration GuidelinesYou can use bridges and switches between LAN segments to form an extended LAN. This can increase availability, distance, and aggregate bandwidth as compared with a single LAN. However, an extended LAN can increase delay and can reduce bandwidth on some paths. Factors such as packet loss, queuing delays, and packet size can also affect network performance. Table 9-3 provides guidelines for ensuring adequate LAN performance when dealing with such factors.
9.3.9 System Parameters for OpenVMS ClustersIn an OpenVMS Cluster with satellites and servers, specific system parameters can help you manage your OpenVMS Cluster more efficiently. Table 9-4 gives suggested values for these system parameters.
1Correlate with bridge timers and LAN utilization. Reference: For more information about these parameters, see HP OpenVMS Cluster Systems and HP Volume Shadowing for OpenVMS. 9.4 Scalability in a Cluster over IPCluster over IP allows a maximum of 96 nodes to be connected across geographical locations along with the support for storage. The usage of extended LAN configuration can be replaced by IP cluster communication. The LAN switches and bridges are replaced by the routers, thus overcoming the disadvantages of the LAN components. The routers can be used for connecting two or more logical subnets, which do not necessarily map one-to-one to the physical interfaces of the router.9.4.1 Multiple node IP based Cluster SystemFigure 9-10 shows an IP based cluster system that has multiple nodes connected to the system. The nodes can be located across different geographical locations thus, enabling disaster tolerance and high availability. Figure 9-10 Multiple node IP based Cluster System 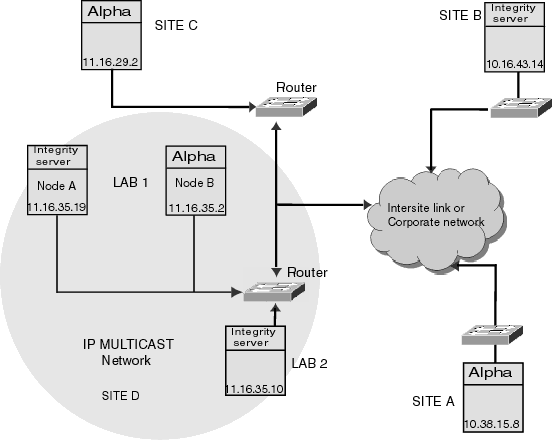
Advantages
9.4.2 Guidelines for Configuring IP based ClusterThe following are the guidelines for setting up a cluster using IP cluster communication:
9.5 Scaling for I/OsThe ability to scale I/Os is an important factor in the growth of your OpenVMS Cluster. Adding more components to your OpenVMS Cluster requires high I/O throughput so that additional components do not create bottlenecks and decrease the performance of the entire OpenVMS Cluster. Many factors can affect I/O throughput:
These factors can affect I/O scalability either singly or in combination. The following sections explain these factors and suggest ways to maximize I/O throughput and scalability without having to change in your application. Additional factors that affect I/O throughput are types of interconnects and types of storage subsystems. Reference: For more information about interconnects, see Chapter 4. For more information about types of storage subsystems, see Chapter 5. For more information about MSCP_BUFFER and MSCP_CREDITS, see HP OpenVMS Cluster Systems.) 9.5.1 MSCP Served Access to StorageMSCP server capability provides a major benefit to OpenVMS Clusters: it enables communication between nodes and storage that are not directly connected to each other. However, MSCP served I/O does incur overhead. Figure 9-11 is a simplification of how packets require extra handling by the serving system. Figure 9-11 Comparison of Direct and MSCP Served Access 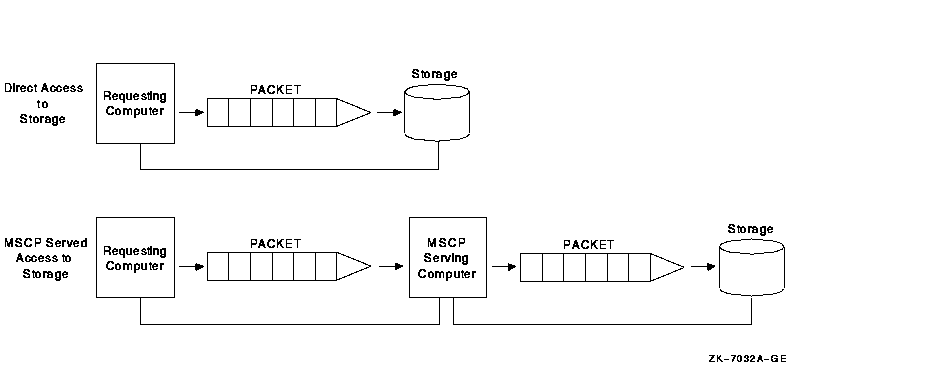
In Figure 9-11, an MSCP served packet requires an extra "stop" at another system before reaching its destination. When the MSCP served packet reaches the system associated with the target storage, the packet is handled as if for direct access. In an OpenVMS Cluster that requires a large amount of MSCP serving, I/O performance is not as efficient and scalability is decreased. The total I/O throughput is approximately 20% less when I/O is MSCP served than when it has direct access. Design your configuration so that a few large nodes are serving many satellites rather than satellites serving their local storage to the entire OpenVMS Cluster. 9.5.2 Disk TechnologiesIn recent years, the ability of CPUs to process information has far outstripped the ability of I/O subsystems to feed processors with data. The result is an increasing percentage of processor time spent waiting for I/O operations to complete. Solid-state disks (SSDs), DECram, and RAID level 0 bridge this gap between processing speed and magnetic-disk access speed. Performance of magnetic disks is limited by seek and rotational latencies, while SSDs and DECram use memory, which provides nearly instant access. RAID level 0 is the technique of spreading (or "striping") a single file across several disk volumes. The objective is to reduce or eliminate a bottleneck at a single disk by partitioning heavily accessed files into stripe sets and storing them on multiple devices. This technique increases parallelism across many disks for a single I/O. Table 9-5 summarizes disk technologies and their features.
Note: Shared, direct access to a solid-state disk or to DECram is the fastest alternative for scaling I/Os. 9.5.3 Read/Write RatioThe read/write ratio of your applications is a key factor in scaling I/O to shadow sets. MSCP writes to a shadow set are duplicated on the interconnect. Therefore, an application that has 100% (100/0) read activity may benefit from volume shadowing because shadowing causes multiple paths to be used for the I/O activity. An application with a 50/50 ratio will cause more interconnect utilization because write activity requires that an I/O be sent to each shadow member. Delays may be caused by the time required to complete the slowest I/O. To determine I/O read/write ratios, use the DCL command MONITOR IO. 9.5.4 I/O SizeEach I/O packet incurs processor and memory overhead, so grouping I/Os together in one packet decreases overhead for all I/O activity. You can achieve higher throughput if your application is designed to use bigger packets. Smaller packets incur greater overhead. 9.5.5 CachesCaching is the technique of storing recently or frequently used data in an area where it can be accessed more easily---in memory, in a controller, or in a disk. Caching complements solid-state disks, DECram, and RAID. Applications automatically benefit from the advantages of caching without any special coding. Caching reduces current and potential I/O bottlenecks within OpenVMS Cluster systems by reducing the number of I/Os between components. Table 9-6 describes the three types of caching.
Host-based disk caching provides different benefits from controller-based and disk-based caching. In host-based disk caching, the cache itself is not shareable among nodes. Controller-based and disk-based caching are shareable because they are located in the controller or disk, either of which is shareable.
|